


Important Computer Vision Papers for the Week from 05/08 to 11/08
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of August 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. An Object is Worth 64x64 Pixels: Generating 3D Object via Image Diffusion

We introduce a new approach for generating realistic 3D models with UV maps through a representation termed “Object Images.” This approach encapsulates surface geometry, appearance, and patch structures within a 64x64 pixel image, effectively converting complex 3D shapes into a more manageable 2D format.
By doing so, we address the challenges of both geometric and semantic irregularity inherent in polygonal meshes. This method allows us to use image generation models, such as Diffusion Transformers, directly for 3D shape generation.
Evaluated on the ABO dataset, our generated shapes with patch structures achieve point cloud FID comparable to recent 3D generative models, while naturally supporting PBR material generation.
2. Vision Language Models (VLMs)
2.1. MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
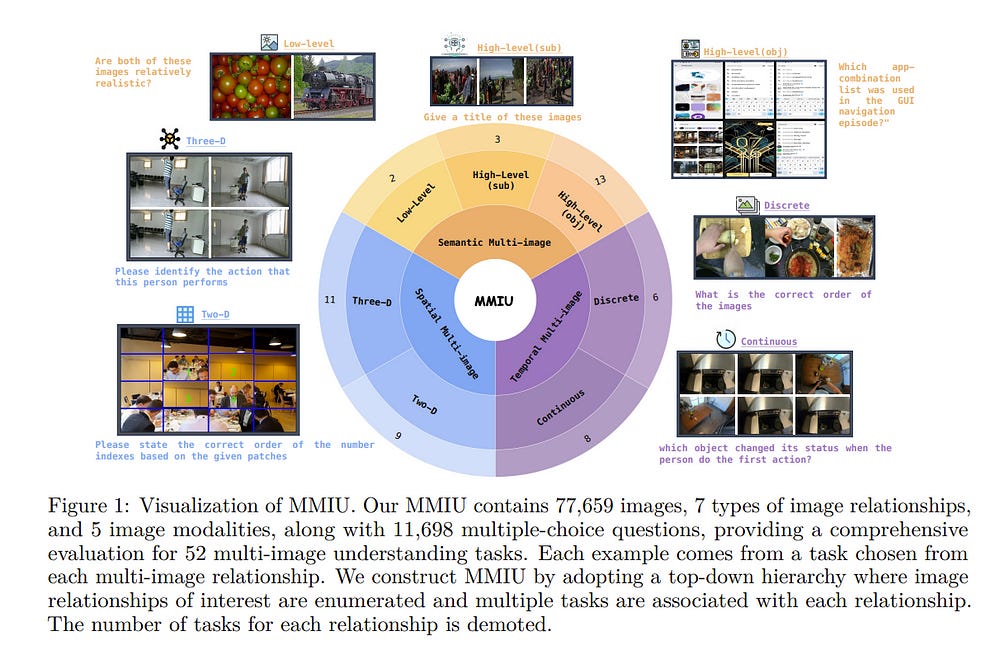
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need.
However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks.
MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind.
Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU.
Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.
2.2. IPAdapter-Instruct: Resolving Ambiguity in Image-based Conditioning using Instruct Prompts

Diffusion models continuously push the boundary of state-of-the-art image generation, but the process is hard to control with any nuance: practice proves that textual prompts are inadequate for accurately describing image style or fine structural details (such as faces).
ControlNet and IPAdapter address this shortcoming by conditioning the generative process on imagery instead, but each individual instance is limited to modeling a single conditional posterior: for practical use cases, where multiple different posteriors are desired within the same workflow, training and using multiple adapters is cumbersome.
We propose IPAdapter-Instruct, which combines natural-image conditioning with ``Instruct’’ prompts to swap between interpretations for the same conditioning image: style transfer, object extraction, both, or something else still? IPAdapterInstruct efficiently learns multiple tasks with minimal loss in quality compared to dedicated per-task models.
2.3. LLaVA-OneVision: Easy Visual Task Transfer

We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series.
Our experimental results demonstrate that LLaVA-OneVision is the first single model that can simultaneously push the performance boundaries of open LMMs in three important computer vision scenarios: single-image, multi-image, and video scenarios.
Importantly, the design of LLaVA-OneVision allows strong transfer learning across different modalities/scenarios, yielding new emerging capabilities. In particular, strong video understanding and cross-scenario capabilities are demonstrated through task transfer from images to videos.
3. Video Understanding & Generation
3.1. VidGen-1M: A Large-Scale Dataset for Text-to-video Generation

The quality of video-text pairs fundamentally determines the upper bound of text-to-video models. Currently, the datasets used for training these models suffer from significant shortcomings, including low temporal consistency, poor-quality captions, substandard video quality, and imbalanced data distribution.
The prevailing video curation process, which depends on image models for tagging and manual rule-based curation, leads to a high computational load and leaves behind unclean data. As a result, there is a lack of appropriate training datasets for text-to-video models.
To address this problem, we present VidGen-1M, a superior training dataset for text-to-video models. Produced through a coarse-to-fine curation strategy, this dataset guarantees high-quality videos and detailed captions with excellent temporal consistency. When used to train the video generation model, this dataset has led to experimental results that surpass those obtained with other models.
4. Image Editing & Generation
4.1. TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing.
To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model.
For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy.
An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map.
Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods.
Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity.
4.2. Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User’s Casual Sketches

3D Content Generation is at the heart of many computer graphics applications, including video gaming, film-making, virtual and augmented reality, etc.
This paper proposes a novel deep-learning based approach for automatically generating interactive and playable 3D game scenes, all from the user’s casual prompts such as a hand-drawn sketch. Sketch-based input offers a natural, and convenient way to convey the user’s design intention in the content creation process.
To circumvent the data-deficient challenge in learning (i.e. the lack of large training data of 3D scenes), our method leverages a pre-trained 2D denoising diffusion model to generate a 2D image of the scene as the conceptual guidance. In this process, we adopt the isometric projection mode to factor out unknown camera poses while obtaining the scene layout.
From the generated isometric image, we use a pre-trained image understanding method to segment the image into meaningful parts, such as off-ground objects, trees, and buildings, and extract the 2D scene layout. These segments and layouts are subsequently fed into a procedural content generation (PCG) engine, such as a 3D video game engine like Unity or Unreal, to create the 3D scene.
The resulting 3D scene can be seamlessly integrated into a game development environment and is readily playable. Extensive tests demonstrate that our method can efficiently generate high-quality and interactive 3D game scenes with layouts that closely follow the user’s intention.
4.3. Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining

We present Lumina-mGPT, a family of multimodal autoregressive models capable of various vision and language tasks, particularly excelling in generating flexible photorealistic images from text descriptions.
Unlike existing autoregressive image generation approaches, Lumina-mGPT employs a pretrained decoder-only transformer as a unified framework for modeling multimodal token sequences.
Our key insight is that a simple decoder-only transformer with multimodal Generative PreTraining (mGPT), utilizing the next-token prediction objective on massive interleaved text-image sequences, can learn broad and general multimodal capabilities, thereby illuminating photorealistic text-to-image generation.
Building on these pretrained models, we propose Flexible Progressive Supervised Finetuning (FP-SFT) on high-quality image-text pairs to fully unlock their potential for high-aesthetic image synthesis at any resolution while maintaining their general multimodal capabilities.
Furthermore, we introduce Ominiponent Supervised Finetuning (Omni-SFT), transforming Lumina-mGPT into a foundation model that seamlessly achieves omnipotent task unification.
The resulting model demonstrates versatile multimodal capabilities, including visual generation tasks like flexible text-to-image generation and controllable generation, visual recognition tasks like segmentation and depth estimation, and vision-language tasks like multiturn visual question answering.
Additionally, we analyze the differences and similarities between diffusion-based and autoregressive methods in a direct comparison.
5. Image Segmentation
5.1. Medical SAM 2: Segment medical images as video via Segment Anything Model 2

In this paper, we introduce Medical SAM 2 (MedSAM-2), an advanced segmentation model that utilizes the SAM 2 framework to address both 2D and 3D medical image segmentation tasks.
By adopting the philosophy of taking medical images as videos, MedSAM-2 not only applies to 3D medical images but also unlocks new One-prompt Segmentation capability.
That allows users to provide a prompt for just one or a specific image targeting an object, after which the model can autonomously segment the same type of object in all subsequent images, regardless of temporal relationships between the images.
We evaluated MedSAM-2 across a variety of medical imaging modalities, including abdominal organs, optic discs, brain tumors, thyroid nodules, and skin lesions, comparing it against state-of-the-art models in both traditional and interactive segmentation settings. Our findings show that MedSAM-2 not only surpasses existing models in performance but also exhibits superior generalization across a range of medical image segmentation tasks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
