


Important Computer Vision Papers for the Week from 16/12 to 22/12
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of December 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Text to Image Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion

Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions.
Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns.
The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors.
To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components.
Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.
1.2. Causal Diffusion Transformers for Generative Modeling

We introduce Causal Diffusion as the autoregressive (AR) counterpart of Diffusion models. It is a next-token(s) forecasting framework that is friendly to both discrete and continuous modalities and compatible with existing next-token prediction models like LLaMA and GPT.
While recent works attempt to combine diffusion with AR models, we show that introducing sequential factorization to a diffusion model can substantially improve its performance and enable a smooth transition between AR and diffusion generation modes.
Hence, we propose CausalFusion — a decoder-only transformer that dual-factorizes data across sequential tokens and diffusion noise levels, leading to state-of-the-art results on the ImageNet generation benchmark while also enjoying the AR advantage of generating an arbitrary number of tokens for in-context reasoning.
We further demonstrate CausalFusion’s multimodal capabilities through a joint image generation and captioning model and showcase CausalFusion’s ability for zero-shot in-context image manipulations. We hope that this work could provide the community with a fresh perspective on training multimodal models over discrete and continuous data.
2. Vision Language Models
2.1. Apollo: An Exploration of Video Understanding in Large Multimodal Models
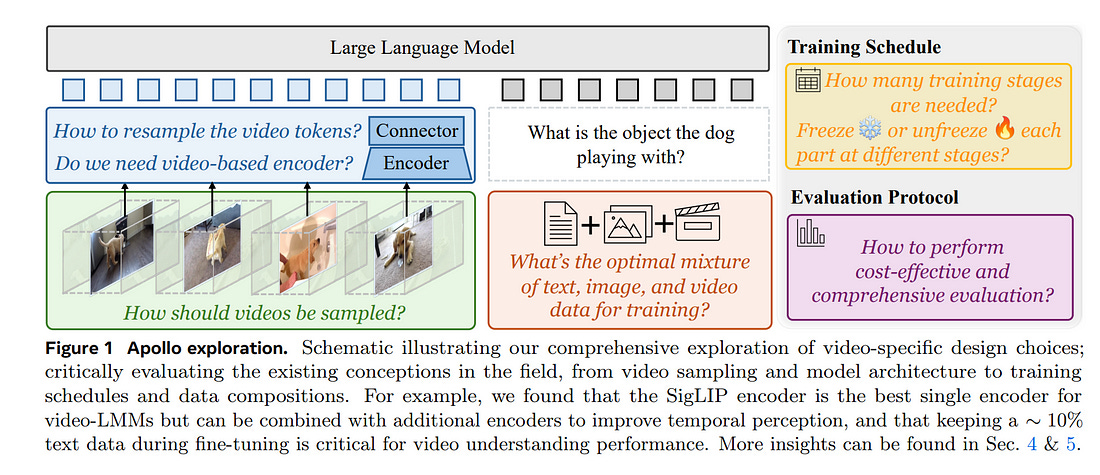
Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood.
Consequently, many design decisions in this domain are made without proper justification or analysis. The high computational cost of training and evaluating such models, coupled with limited open research, hinders the development of video-LMMs.
To address this, we present a comprehensive study that helps uncover what effectively drives video understanding in LMMs. We begin by critically examining the primary contributors to the high computational requirements associated with video-LMM research and discover Scaling Consistency, wherein design and training decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models.
Leveraging these insights, we explored many video-specific aspects of video-LMMs, including video sampling, architectures, data composition, training schedules, and more.
For example, we demonstrated that fps sampling during training is vastly preferable to uniform frame sampling and which vision encoders are the best for video representation.
Guided by these findings, we introduce Apollo, a state-of-the-art family of LMMs that achieve superior performance across different model sizes. Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing 7B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MME.
2.2. Evaluation Agent: Efficient and Promptable Evaluation Framework for Visual Generative Models

Recent advancements in visual generative models have enabled high-quality image and video generation, opening diverse applications.
However, evaluating these models often demands sampling hundreds or thousands of images or videos, making the process computationally expensive, especially for diffusion-based models with inherently slow sampling.
Moreover, existing evaluation methods rely on rigid pipelines that overlook specific user needs and provide numerical results without clear explanations.
In contrast, humans can quickly form impressions of a model’s capabilities by observing only a few samples. To mimic this, we propose the Evaluation Agent framework, which employs human-like strategies for efficient, dynamic, multi-round evaluations using only a few samples per round, while offering detailed, user-tailored analyses.
It offers four key advantages: 1) efficiency, 2) promptable evaluation tailored to diverse user needs, 3) explainability beyond single numerical scores, and 4) scalability across various models and tools.
Experiments show that the Evaluation Agent reduces evaluation time to 10% of traditional methods while delivering comparable results. The Evaluation Agent framework is fully open-sourced to advance research in visual generative models and their efficient evaluation.
3. Video Generation & Editing
3.1. InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
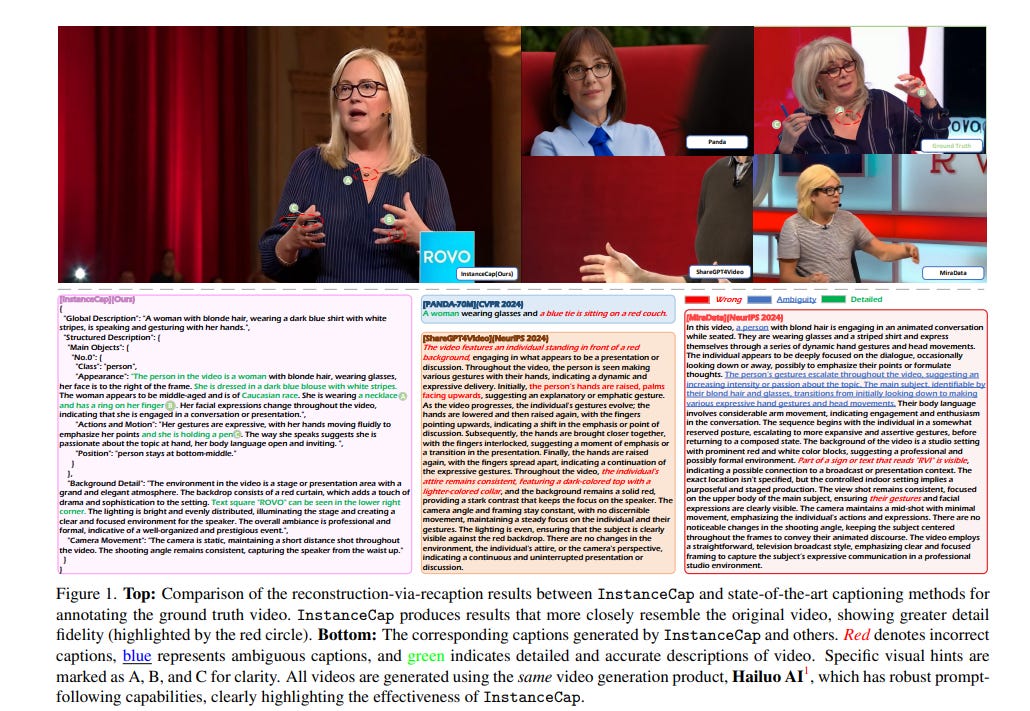
Text-to-video generation has evolved rapidly in recent years, delivering remarkable results. Training typically relies on video-caption paired data, which plays a crucial role in enhancing generation performance.
However, current video captions often suffer from insufficient details, hallucinations, and imprecise motion depiction, affecting the fidelity and consistency of generated videos.
In this work, we propose a novel instance-aware structured caption framework, termed InstanceCap, to achieve instance-level and fine-grained video captioning for the first time.
Based on this scheme, we design an auxiliary models cluster to convert original videos into instances to enhance instance fidelity. Video instances are further used to refine dense prompts into structured phrases, achieving concise yet precise descriptions.
Furthermore, a 22K InstanceVid dataset is curated for training, and an enhancement pipeline that is tailored to the InstanceCap structure is proposed for inference.
Experimental results demonstrate that our proposed InstanceCap significantly outperforms previous models, ensuring high fidelity between captions and videos while reducing hallucinations.
3.2. LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity

Text-to-video generation enhances content creation but is highly computationally intensive: The computational cost of Diffusion Transformers (DiTs) scales quadratically in the number of pixels.
This makes minute-length video generation extremely expensive, limiting most existing models to generating videos of only 10–20 seconds in length. We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels.
For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality. It replaces the computationally dominant and quadratic-complexity block, self-attention, with a linear-complexity block called MATE, which consists of an MA-branch and a TE-branch.
The MA-branch targets short-to-long-range correlations, combining a bidirectional Mamba2 block with our token rearrangement method, Rotary Major Scan, and our review tokens developed for long video generation.
The TE-branch is a novel TEmporal Swin Attention block that focuses on temporal correlations between adjacent tokens and medium-range tokens. The MATE block addresses the adjacency preservation issue of Mamba and significantly improves the generated videos' consistency.
Experimental results show that LinGen outperforms DiT (with a 75.6% win rate) in video quality with up to 15 times (11.5 times) FLOPs (latency) reduction.
Furthermore, both automatic metrics and human evaluation demonstrate our LinGen-4B yields comparable video quality to state-of-the-art models (with a 50.5%, 52.1%, and 49.1% win rate with respect to Gen-3, LumaLabs, and Kling, respectively). This paves the way to hour-length movie generation and real-time interactive video generation.
4. Text to Image Generation
4.1. GenEx: Generating an Explorable World

Understanding, navigating, and exploring the 3D physical real world has long been a central challenge in the development of artificial intelligence.
In this work, we take a step toward this goal by introducing GenEx, a system capable of planning complex embodied world exploration, guided by its generative imagination that forms priors (expectations) about the surrounding environments.
GenEx generates an entire 3D-consistent imaginative environment from as little as a single RGB image, bringing it to life through panoramic video streams. Leveraging scalable 3D world data curated from Unreal Engine, our generative model is rounded in the physical world.
It captures a continuous 360-degree environment with little effort, offering a boundless landscape for AI agents to explore and interact with. GenEx achieves high-quality world generation, and robust loop consistency over long trajectories, and demonstrates strong 3D capabilities such as consistency and active 3D mapping.
Powered by the generative imagination of the world, GPT-assisted agents are equipped to perform complex embodied tasks, including both goal-agnostic exploration and goal-driven navigation.
These agents utilize predictive expectations regarding unseen parts of the physical world to refine their beliefs, simulate different outcomes based on potential decisions, and make more informed choices.
In summary, we demonstrate that GenEx provides a transformative platform for advancing embodied AI in imaginative spaces and brings the potential for extending these capabilities to real-world exploration.
4.2. SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vision Experts and Token Folding
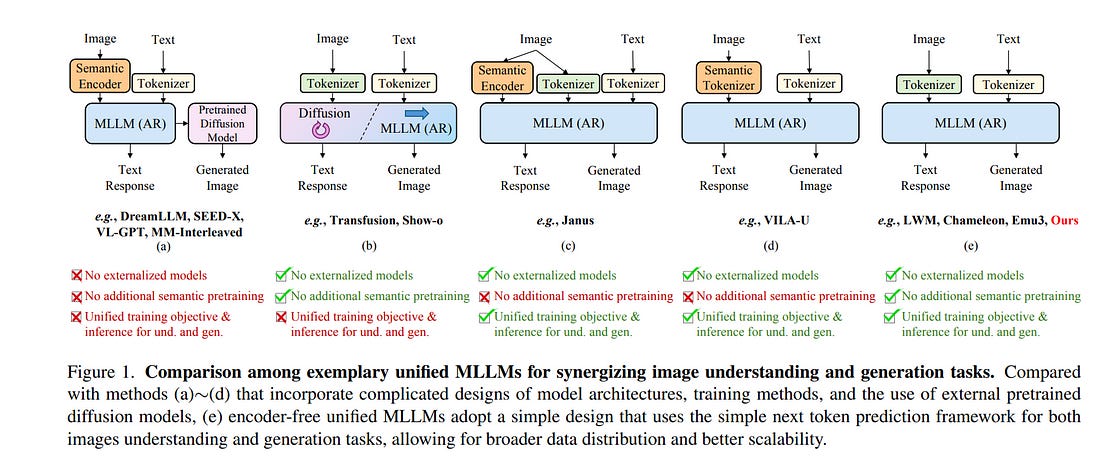
The remarkable success of Large Language Models (LLMs) has extended to the multimodal domain, achieving outstanding performance in image understanding and generation.
Recent efforts to develop unified Multimodal Large Language Models (MLLMs) that integrate these capabilities have shown promising results. However, existing approaches often involve complex designs in model architecture or training pipelines, increasing the difficulty of model training and scaling.
In this paper, we propose SynerGen-VL, a simple yet powerful encoder-free MLLM capable of both image understanding and generation. To address challenges identified in existing encoder-free unified MLLMs, we introduce the token folding mechanism and the vision-expert-based progressive alignment pretraining strategy, which effectively support high-resolution image understanding while reducing training complexity.
After being trained on large-scale mixed image-text data with a unified next-token prediction objective, SynerGen-VL achieves or surpasses the performance of existing encoder-free unified MLLMs with comparable or smaller parameter sizes, and narrows the gap with task-specific state-of-the-art models, highlighting a promising path toward future unified MLLMs.
4.3. FashionComposer: Compositional Fashion Image Generation

We present FashionComposer for compositional fashion image generation. Unlike previous methods, FashionComposer is highly flexible. It takes multi-modal input (i.e., text prompt, parametric human model, garment image, and face image) and supports personalizing the appearance, pose, and figure of the human and assigning multiple garments in one pass.
To achieve this, we first develop a universal framework capable of handling diverse input modalities. We construct scaled training data to enhance the model’s robust compositional capabilities.
To accommodate multiple reference images (garments and faces) seamlessly, we organize these references in a single image as an “asset library” and employ a reference UNet to extract appearance features. To inject the appearance features into the correct pixels in the generated result, we propose subject-binding attention.
It binds the appearance features from different “assets” with the corresponding text features. In this way, the model could understand each asset according to their semantics, supporting arbitrary numbers and types of reference images. As a comprehensive solution, FashionComposer also supports many other applications like human album generation, diverse virtual try-on tasks, etc.
4.4. AniDoc: Animation Creation Made Easier

The production of 2D animation follows an industry-standard workflow, encompassing four essential stages: character design, keyframe animation, in-betweening, and coloring.
Our research focuses on reducing labor costs in the above process by harnessing the potential of increasingly powerful generative AI. Using video diffusion models as the foundation, AniDoc emerges as a video line art colorization tool, automatically converting sketch sequences into colored animations following the reference character specification.
Our model exploits correspondence matching as explicit guidance, yielding strong robustness to the variations (e.g., posture) between the reference character and each line art frame.
In addition, our model could automate the in-betweening process, such that users can easily create a temporally consistent animation by simply providing a character image as well as the start and end sketches.
4.5. BrushEdit: All-In-One Image Inpainting and Editing

Image editing has advanced significantly with the development of diffusion models using both inversion-based and instruction-based methods. However, current inversion-based approaches struggle with big modifications (e.g., adding or removing objects) due to the structured nature of inversion noise, which hinders substantial changes.
Meanwhile, instruction-based methods often constrain users to black-box operations, limiting direct interaction for specifying editing regions and intensity.
To address these limitations, we propose BrushEdit, a novel inpainting-based instruction-guided image editing paradigm, which leverages multimodal large language models (MLLMs) and image inpainting models to enable autonomous, user-friendly, and interactive free-form instruction editing.
Specifically, we devise a system enabling free-form instruction editing by integrating MLLMs and a dual-branch image inpainting model in an agent-cooperative framework to perform editing category classification, main object identification, mask acquisition, and editing area inpainting.
Extensive experiments show that our framework effectively combines MLLMs and inpainting models, achieving superior performance across seven metrics including mask region preservation and editing effect coherence.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
