


Important Computer Vision Papers for the Week from 13/01 to 19/01
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third week of January 2025, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. Diffusion Models
1.1. Inference-Time Scaling for Diffusion Models Beyond Scaling Denoising Steps

Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws.
Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen.
In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can be further improved with increased computation. Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process.
We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time computing leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
2. Vision Language Models
2.1. LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs

Reasoning is a fundamental capability for solving complex multi-step problems, particularly in visual contexts where sequential step-wise understanding is essential. Existing approaches lack a comprehensive framework for evaluating visual reasoning and do not emphasize step-wise problem-solving.
To this end, we propose a comprehensive framework for advancing step-by-step visual reasoning in large language models (LMMs) through three key contributions.
First, we introduce a visual reasoning benchmark specifically designed to evaluate multi-step reasoning tasks. The benchmark presents a diverse set of challenges with eight different categories ranging from complex visual perception to scientific reasoning with over 4k reasoning steps in total, enabling robust evaluation of LLMs’ abilities to perform accurate and interpretable visual reasoning across multiple steps.
Second, we propose a novel metric that assesses visual reasoning quality at the granularity of individual steps, emphasizing both correctness and logical coherence. The proposed metric offers deeper insights into reasoning performance compared to traditional end-task accuracy metrics.
Third, we present a new multimodal visual reasoning model, named LlamaV-o1, trained using a multi-step curriculum learning approach, where tasks are progressively organized to facilitate incremental skill acquisition and problem-solving.
The proposed LlamaV-o1 is designed for multi-step reasoning and learns step-by-step through a structured training paradigm. Extensive experiments show that our LlamaV-o1 outperforms existing open-source models and performs favorably against closed-source proprietary models.
Compared to the recent Llava-CoT, our LlamaV-o1 achieves an average score of 67.3 with an absolute gain of 3.8\% across six benchmarks while being 5 times faster during inference scaling. Our benchmark, model, and code are publicly available.
2.2. VideoRAG: Retrieval-Augmented Generation over Video Corpus

Retrieval-augmented generation (RAG) is a powerful strategy to address the issue of generating factually incorrect outputs in foundation models by retrieving external knowledge relevant to queries and incorporating it into their generation process.
However, existing RAG approaches have primarily focused on textual information, with some recent advancements beginning to consider images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing events, processes, and contextual details more effectively than any other modality.
While a few recent studies explore the integration of videos in the response generation process, they either predefine query-associated videos without retrieving them according to queries or convert videos into textual descriptions without harnessing their multimodal richness.
To tackle these, we introduce VideoRAG, a novel framework that not only dynamically retrieves relevant videos based on their relevance with queries but also utilizes both visual and textual information of videos in the output generation.
Further, to operationalize this, our method revolves around the recent advance of Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and seamless integration of the retrieved videos jointly with queries. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines.
2.3. FAST: Efficient Action Tokenization for Vision-Language-Action Models

Autoregressive sequence models, such as Transformer-based vision-language action (VLA) policies, can be tremendously effective for capturing complex and generalizable robotic behaviors.
However, such models require us to choose a tokenization of our continuous action signals, which determines how the discrete symbols predicted by the model map to continuous robot actions.
We find that current approaches for robot action tokenization, based on simple per-dimension, per-timestep binning schemes, typically perform poorly when learning dexterous skills from high-frequency robot data.
To address this challenge, we propose a new compression-based tokenization scheme for robot actions, based on the discrete cosine transform. Our tokenization approach, Frequency-space Action Sequence Tokenization (FAST), enables us to train autoregressive VLAs for highly dexterous and high-frequency tasks where standard discretization methods fail completely.
Based on FAST, we release FAST+, a universal robot action tokenizer, trained on 1M real robot action trajectories. It can be used as a black-box tokenizer for a wide range of robot action sequences, with diverse action spaces and control frequencies.
Finally, we show that, when combined with the pi0 VLA, our method can scale to training on 10k hours of robot data and match the performance of diffusion VLAs, while reducing training time by up to 5x.
3. Video Generation & Editing
3.1. Do generative video models learn physical principles from watching videos?

AI video generation is revolutionizing, with quality and realism advancing rapidly. These advances have led to a passionate scientific debate: Do video models learn ``world models’’ that discover laws of physics — or are they merely sophisticated pixel predictors that achieve visual realism without understanding the physical principles of reality?
We address this question by developing Physics-IQ, a comprehensive benchmark dataset that can only be solved by acquiring a deep understanding of various physical principles, like fluid dynamics, optics, solid mechanics, magnetism, and thermodynamics.
We find that across a range of current models (Sora, Runway, Pika, Lumiere, Stable Video Diffusion, and VideoPoet), physical understanding is severely limited and unrelated to visual realism. At the same time, some test cases can already be successfully solved.
This indicates that acquiring certain physical principles from observation alone may be possible, but significant challenges remain. While we expect rapid advances ahead, our work demonstrates that visual realism does not imply physical understanding.
3.2. VideoAuteur: Towards Long Narrative Video Generation

Recent video generation models have shown promising results in producing high-quality video clips lasting several seconds. However, these models face challenges in generating long sequences that convey clear and informative events, limiting their ability to support coherent narrations.
In this paper, we present a large-scale cooking video dataset designed to advance long-form narrative generation in the cooking domain. We validate the quality of our proposed dataset in terms of visual fidelity and textual caption accuracy using state-of-the-art Vision-Language Models (VLMs) and video generation models, respectively.
We further introduce a Long Narrative Video Director to enhance both visual and semantic coherence in generated videos and emphasize the role of aligning visual embeddings to achieve improved overall video quality.
Our method demonstrates substantial improvements in generating visually detailed and semantically aligned keyframes, supported by finetuning techniques that integrate text and image embeddings within the video generation process.
3.3. OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
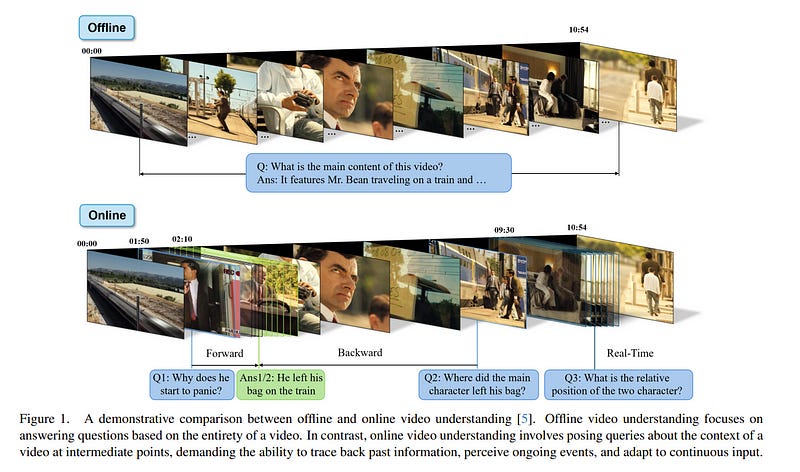
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed.
Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios:
Backward tracing: trace back to past events to answer the question.
Real-time understanding: understand and respond to events as they unfold at the current timestamp.
Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately.
OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps.
We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline.
Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents.
We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning.
3.4. Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks

We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space.
These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens.
To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video.
Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
