
Important Computer Vision Papers for the Week from 23/12 to 29/12
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth and final Week of December 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Text to Image Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. CLEAR: Conv-Like Linearization Revs Pre-Trained Diffusion Transformers Up

Diffusion Transformers (DiT) have become a leading architecture in image generation. However, the quadratic complexity of attention mechanisms, which are responsible for modeling token-wise relationships, results in significant latency when generating high-resolution images.
To address this issue, we aim at a linear attention mechanism in this paper that reduces the complexity of pre-trained DiTs to linear. We begin our exploration with a comprehensive summary of existing efficient attention mechanisms and identify four key factors crucial for the successful linearization of pre-trained DiTs: locality, formulation consistency, high-rank attention maps, and feature integrity.
Based on these insights, we introduce a convolution-like local attention strategy termed CLEAR, which limits feature interactions to a local window around each query token, and thus achieves linear complexity.
Our experiments indicate that, by fine-tuning the attention layer on merely 10K self-generated samples for 10K iterations, we can effectively transfer knowledge from a pre-trained DiT to a student model with linear complexity, yielding results comparable to the teacher model.
Simultaneously, it reduces attention computations by 99.5% and accelerates generation by 6.3 times for generating 8K-resolution images. Furthermore, we investigate favorable properties in the distilled attention layers, such as zero-shot generalization across various models and plugins, and improved support for multi-GPU parallel inference.
1.2. DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation

Sora-like video generation models have achieved remarkable progress with a Multi-Modal Diffusion Transformer MM-DiT architecture. However, the current video generation models predominantly focus on single-prompt, struggling to generate coherent scenes with multiple sequential prompts that better reflect real-world dynamic scenarios.
While some pioneering works have explored multi-prompt video generation, they face significant challenges including strict training data requirements, weak prompt following, and unnatural transitions. To address these problems, we propose DiTCtrl, a training-free multi-prompt video generation method under MM-DiT architectures for the first time.
Our key idea is to take the multi-prompt video generation task as temporal video editing with smooth transitions. To achieve this goal, we first analyze MM-DiT’s attention mechanism, finding that the 3D full attention behaves similarly to that of the cross/self-attention blocks in the UNet-like diffusion models, enabling mask-guided precise semantic control across different prompts with attention sharing for multi-prompt video generation.
Based on our careful design, the video generated by DiTCtrl achieves smooth transitions and consistent object motion given multiple sequential prompts without additional training.
Besides, we also present MPVBench, a new benchmark specially designed for multi-prompt video generation to evaluate the performance of multi-prompt generation. Extensive experiments demonstrate that our method achieves state-of-the-art performance without additional training.
2. Vision Language Models
2.1. MMFactory: A Universal Solution Search Engine for Vision-Language Tasks

With advances in foundational and vision-language models, and effective fine-tuning techniques, a large number of both general and special-purpose models have been developed for a variety of visual tasks.
Despite the flexibility and accessibility of these models, no single model is able to handle all tasks and/or applications that may be envisioned by potential users. Recent approaches, such as visual programming and multimodal LLMs with integrated tools aim to tackle complex visual tasks, by way of program synthesis.
However, such approaches overlook user constraints (e.g., performance / computational needs), produce test-time sample-specific solutions that are difficult to deploy, and, sometimes, require low-level instructions that may be beyond the abilities of a naive user.
To address these limitations, we introduce MMFactory, a universal framework that includes model and metrics routing components, acting like a solution search engine across various available models.
Based on a task description and a few sample input-output pairs and (optionally) resource and/or performance constraints, MMFactory can suggest a diverse pool of programmatic solutions by instantiating and combining visio-lingual tools from its model repository.
In addition to synthesizing these solutions, MMFactory also proposes metrics and benchmarks performance/resource characteristics, allowing users to pick a solution that meets their unique design constraints.
From the technical perspective, we also introduced a committee-based solution proposer that leverages multi-agent LLM conversation to generate executable, diverse, universal, and robust solutions for the user.
Experimental results show that MMFactory outperforms existing methods by delivering state-of-the-art solutions tailored to user problem specifications.
2.2. Video-Panda: Parameter-efficient Alignment for Encoder-free Video-Language Models
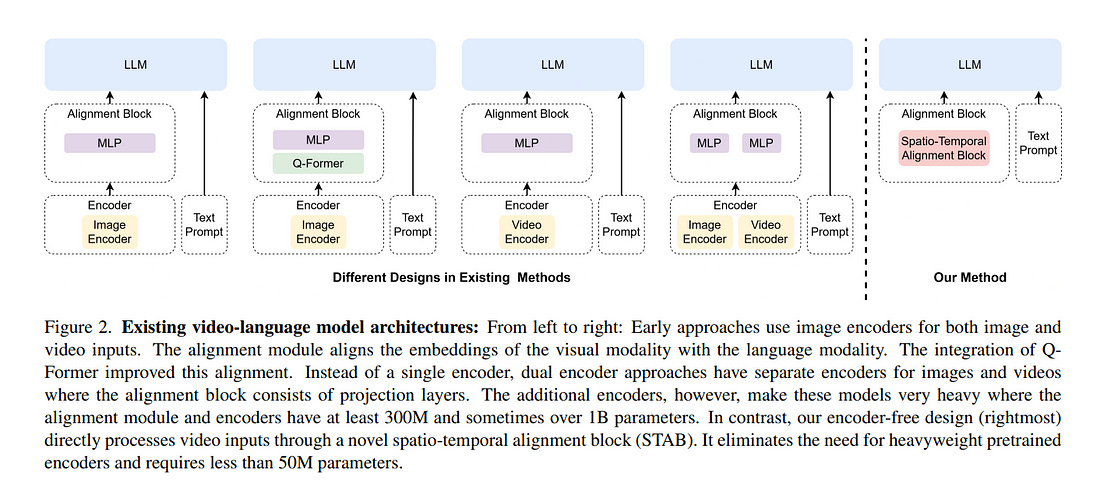
We present an efficient encoder-free approach for video-language understanding that achieves competitive performance while significantly reducing computational overhead.
Current video-language models typically rely on heavyweight image encoders (300M-1.1B parameters) or video encoders (1B-1.4B parameters), creating a substantial computational burden when processing multi-frame videos.
Our method introduces a novel Spatio-Temporal Alignment Block (STAB) that directly processes video inputs without requiring pre-trained encoders while using only 45M parameters for visual processing — at least a 6.5 times reduction compared to traditional approaches.
The STAB architecture combines Local Spatio-Temporal Encoding for fine-grained feature extraction, efficient spatial downsampling through learned attention, and separate mechanisms for modeling frame-level and video-level relationships.
Our model achieves comparable or superior performance to encoder-based approaches for open-ended video question answering on standard benchmarks.
The fine-grained video question-answering evaluation demonstrates our model’s effectiveness, outperforming the encoder-based approaches Video-ChatGPT and Video-LLaVA in key aspects like correctness and temporal understanding.
Extensive ablation studies validate our architectural choices and demonstrate the effectiveness of our spatio-temporal modeling approach while achieving 3–4 times faster processing speeds than previous methods.
3. Video Generation & Editing
3.1. Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis

We propose to synthesize high-quality and synchronized audio, given video and optional text conditions, using a novel multimodal joint training framework MMAudio.
In contrast to single-modality training conditioned on (limited) video data only, MMAudio is jointly trained with larger-scale, readily available text-audio data to learn to generate semantically aligned high-quality audio samples.
Additionally, we improve audio-visual synchrony with a conditional synchronization module that aligns video conditions with audio latents at the frame level.
Trained with a flow matching objective, MMAudio achieves new video-to-audio state-of-the-art among public models in terms of audio quality, semantic alignment, and audio-visual synchronization, while having a low inference time (1.23s to generate an 8s clip) and just 157M parameters.
MMAudio also achieves surprisingly competitive performance in text-to-audio generation, showing that joint training does not hinder single-modality performance.
3.2. TRecViT: A Recurrent Video Transformer

We propose a novel block for video modeling. It relies on a time-space-channel factorization with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels.
The resulting architecture TRecViT performs well on sparse and dense tasks and is trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large-scale video datasets (SSv2, Kinetics400), while having 3 times fewer parameters, 12 times smaller memory footprint, and 5 times lower FLOPs count.
3.3. Large Motion Video Autoencoding with Cross-modal Video VAE

Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression.
Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding.
First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts.
Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression.
Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability.
Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method.
4. Text to Image Generation
4.1. Parallelized Autoregressive Visual Generation

Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process.
In this paper, we propose a simple yet effective approach for parallelized autoregressive visual generation that improves generation efficiency while preserving the advantages of autoregressive modeling.
Our key insight is that parallel generation depends on visual token dependencies- tokens with weak dependencies can be generated in parallel, while strongly dependent adjacent tokens are difficult to generate together, as their independent sampling may lead to inconsistencies.
Based on this observation, we develop a parallel generation strategy that generates distant tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent local tokens.
Our approach can be seamlessly integrated into standard autoregressive models without modifying the architecture or tokenizer. Experiments on ImageNet and UCF-101 demonstrate that our method achieves a 3.6x speedup with comparable quality and up to a 9.5x speedup with minimal quality degradation across both image and video generation tasks. We hope this work will inspire future research in efficient visual generation and unified autoregressive modeling.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
