


Important Computer Vision Papers for the Week from 21/10 to 27/10
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of October 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Generation & Editing
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. MagicTailor: Component-Controllable Personalization in Text-to-Image Diffusion Models

Recent advancements in text-to-image (T2I) diffusion models have enabled the creation of high-quality images from text prompts, but they still struggle to generate images with precise control over specific visual concepts.
Existing approaches can replicate a given concept by learning from reference images, yet they lack the flexibility for fine-grained customization of the individual component within the concept.
In this paper, we introduce component-controllable personalization, a novel task that pushes the boundaries of T2I models by allowing users to reconfigure specific components when personalizing visual concepts.
This task is particularly challenging due to two primary obstacles: semantic pollution, where unwanted visual elements corrupt the personalized concept, and semantic imbalance, which causes disproportionate learning of the concept and component.
To overcome these challenges, we design MagicTailor, an innovative framework that leverages Dynamic Masked Degradation (DM-Deg) to dynamically perturb undesired visual semantics and Dual-Stream Balancing (DS-Bal) to establish a balanced learning paradigm for desired visual semantics.
Extensive comparisons, ablations, and analyses demonstrate that MagicTailor not only excels in this challenging task but also holds significant promise for practical applications, paving the way for more nuanced and creative image generation.
1.2. FiTv2: Scalable and Improved Flexible Vision Transformer for Diffusion Model

Nature is infinitely resolution-free. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain.
To address this limitation, we conceptualize images as sequences of tokens with dynamic sizes, rather than traditional methods that perceive images as fixed-resolution grids.
This perspective enables a flexible training strategy that seamlessly accommodates various aspect ratios during both training and inference, thus promoting resolution generalization and eliminating biases introduced by image cropping.
On this basis, we present the Flexible Vision Transformer (FiT), a transformer architecture specifically designed for generating images with unrestricted resolutions and aspect ratios.
We further upgrade the FiT to FiTv2 with several innovative designs, including the Query-Key vector normalization, the AdaLN-LoRA module, a rectified flow scheduler, and a Logit-Normal sampler. Enhanced by a meticulously adjusted network structure, FiTv2 exhibits 2 times the convergence speed of FiT.
When incorporating advanced training-free extrapolation techniques, FiTv2 demonstrates remarkable adaptability in both resolution extrapolation and diverse resolution generation.
Additionally, our exploration of the scalability of the FiTv2 model reveals that larger models exhibit better computational efficiency. Furthermore, we introduce an efficient post-training strategy to adapt a pre-trained model for the high-resolution generation. Comprehensive experiments demonstrate the exceptional performance of FiTv2 across a broad range of resolutions.
2. Vision Language Models (VLMs)
2.1. PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction

In large vision-language models (LVLMs), images serve as inputs that carry a wealth of information. As the idiom “A picture is worth a thousand words” implies, representing a single image in current LVLMs can require hundreds or even thousands of tokens.
This results in significant computational costs, which grow quadratically as input image resolution increases, thereby severely impacting the efficiency of both training and inference.
Previous approaches have attempted to reduce the number of image tokens either before or within the early layers of LVLMs. However, these strategies inevitably result in the loss of crucial image information, ultimately diminishing model performance.
To address this challenge, we conduct an empirical study revealing that all visual tokens are necessary for LVLMs in the shallow layers, and token redundancy progressively increases in the deeper layers of the model.
To this end, we propose PyramidDrop, a visual redundancy reduction strategy for LVLMs to boost their efficiency in both training and inference with neglectable performance loss.
Specifically, we partition the LVLM into several stages and drop part of the image tokens at the end of each stage with a pre-defined ratio, creating pyramid-like visual tokens across model layers.
The dropping is based on a lightweight similarity calculation with a negligible time overhead. Extensive experiments demonstrate that PyramidDrop can achieve a 40% training time and 55% inference FLOPs acceleration of LLaVA-NeXT with comparable performance.
Besides, the PyramidDrop could also serve as a plug-and-play strategy for inference acceleration without training, with better performance and lower inference cost than counterparts.
We hope that the insights and approach introduced by PyramidDrop will inspire future research to further investigate the role of image tokens in LVLMs.
2.2. Improve Vision Language Model Chain-of-thought Reasoning
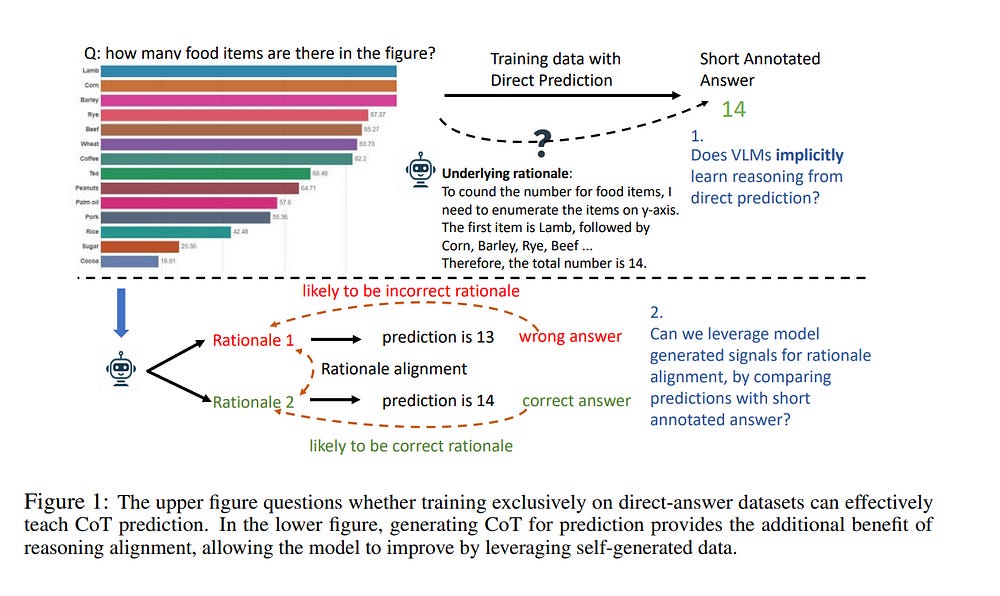
Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness. However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales.
In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses. To address this, we propose a two-fold approach.
First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance. Second, we apply reinforcement learning to further calibrate reasoning quality.
Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers. Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model’s reasoning abilities.
Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well.
This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
2.3. Distill Visual Chart Reasoning Ability from LLMs to MLLMs

Solving complex chart Q&A tasks requires advanced visual reasoning abilities in multimodal large language models (MLLMs). Recent studies highlight that these abilities consist of two main parts: recognizing key information from visual inputs and conducting reasoning over it.
Thus, a promising approach to enhance MLLMs is to construct relevant training data focusing on the two aspects. However, collecting and annotating complex charts and questions is costly and time-consuming, and ensuring the quality of annotated answers remains a challenge.
In this paper, we propose Code-as-Intermediary Translation (CIT), a cost-effective, efficient, and easily scalable data synthesis method for distilling visual reasoning abilities from LLMs to MLLMs.
The code serves as an intermediary that translates visual chart representations into textual representations, enabling LLMs to understand cross-modal information.
Specifically, we employ text-based synthesizing techniques to construct chart-plotting code and produce ReachQA, a dataset containing 3k reasoning-intensive charts and 20k Q&A pairs to enhance both recognition and reasoning abilities.
Experiments show that when fine-tuned with our data, models not only perform well on chart-related benchmarks but also demonstrate improved multimodal reasoning abilities on general mathematical benchmarks like MathVista.
2.4. xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs

We present xGen-MM-Vid (BLIP-3-Video): a multimodal language model for videos, particularly designed to efficiently capture temporal information over multiple frames.
BLIP-3-Video takes advantage of the ‘temporal encoder’ in addition to the conventional visual tokenizer, which maps a sequence of tokens over multiple frames into a compact set of visual tokens.
This enables BLIP3-Video to use much fewer visual tokens than its competing models (e.g., 32 vs. 4608 tokens). We explore different types of temporal encoders, including learnable spatio-temporal pooling as well as sequential models like Token Turing Machines.
We experimentally confirm that BLIP-3-Video obtains video question-answering accuracies comparable to much larger state-of-the-art models (e.g., 34B), while being much smaller (i.e., 4B) and more efficient by using fewer visual tokens.
2.5. MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large Vision-Language Models
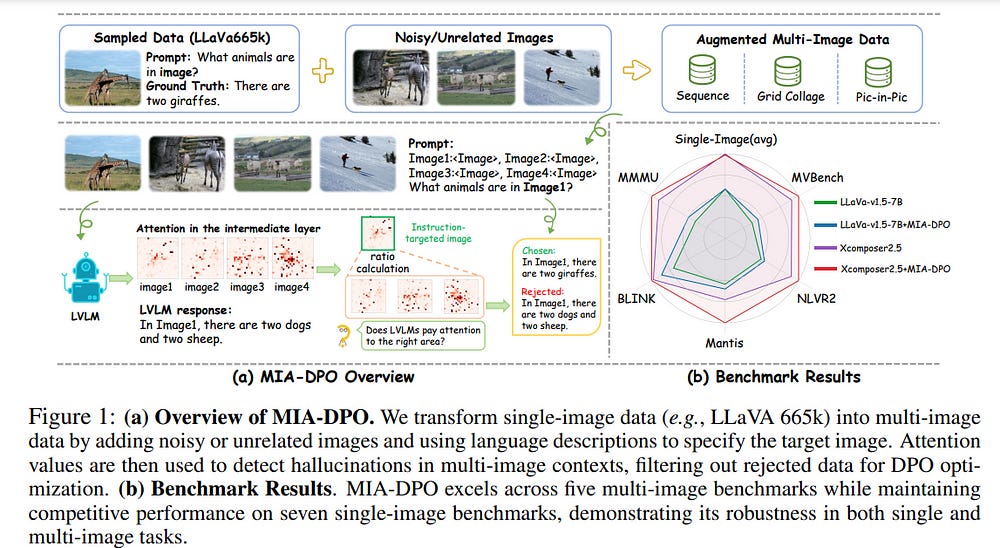
Visual preference alignment involves training Large Vision-Language Models (LVLMs) to predict human preferences between visual inputs. This is typically achieved by using labeled datasets of chosen/rejected pairs and employing optimization algorithms like direct preference optimization (DPO).
Existing visual alignment methods, primarily designed for single-image scenarios, struggle to effectively handle the complexity of multi-image tasks due to the scarcity of diverse training data and the high cost of annotating chosen/rejected pairs. We present Multi-Image Augmented Direct Preference Optimization (MIA-DPO), a visual preference alignment approach that effectively handles multi-image inputs.
MIA-DPO mitigates the scarcity of diverse multi-image training data by extending single-image data with unrelated images arranged in grid collages or pic-in-pic formats, significantly reducing the costs associated with multi-image data annotations.
Our observation reveals that attention values of LVLMs vary considerably across different images. We use attention values to identify and filter out rejected responses the model may have mistakenly focused on.
Our attention-aware selection for constructing the chosen/rejected pairs without relying on (i) human annotation, (ii) extra data, and (iii) external models or APIs. MIA-DPO is compatible with various architectures and outperforms existing methods on five multi-image benchmarks, achieving an average performance boost of 3.0% on LLaVA-v1.5 and 4.3% on the recent InternLM-XC2.5. Moreover, MIA-DPO has a minimal effect on the model’s ability to understand single images.
3. Image Generation & Editing
3.1. PUMA: Empowering Unified MLLM with Multi-granular Visual Generation

Recent advancements in multimodal foundation models have yielded significant progress in vision-language understanding. Initial attempts have also explored the potential of multimodal large language models (MLLMs) for visual content generation.
However, existing works have insufficiently addressed the varying granularity demands of different image generation tasks within a unified MLLM paradigm — from the diversity required in text-to-image generation to the precise controllability needed in image manipulation.
In this work, we propose PUMA, emPowering Unified MLLM with Multi-grAnular visual generation. PUMA unifies multi-granular visual features as both inputs and outputs of MLLMs, elegantly addressing the different granularity requirements of various image generation tasks within a unified MLLM framework.
Following multimodal pretraining and task-specific instruction tuning, PUMA demonstrates proficiency in a wide range of multimodal tasks. This work represents a significant step towards a truly unified MLLM capable of adapting to the granularity demands of various visual tasks.
4. Video Generation & Editing
4.1. WorldSimBench: Towards Video Generation Models as World Simulators

Recent advancements in predictive models have demonstrated exceptional capabilities in predicting the future state of objects and scenes. However, the lack of categorization based on inherent characteristics continues to hinder the progress of predictive model development.
Additionally, existing benchmarks are unable to effectively evaluate higher-capability, highly embodied predictive models from an embodied perspective. In this work, we classify the functionalities of predictive models into a hierarchy and take the first step in evaluating World Simulators by proposing a dual evaluation framework called WorldSimBench.
WorldSimBench includes Explicit Perceptual Evaluation and Implicit Manipulative Evaluation, encompassing human preference assessments from the visual perspective and action-level evaluations in embodied tasks, covering three representative embodied scenarios: Open-Ended Embodied Environment, Autonomous, Driving, and Robot Manipulation.
In the Explicit Perceptual Evaluation, we introduce the HF-Embodied Dataset, a video assessment dataset based on fine-grained human feedback, which we use to train a Human Preference Evaluator that aligns with human perception and explicitly assesses the visual fidelity of World Simulators.
In the Implicit Manipulative Evaluation, we assess the video-action consistency of World Simulators by evaluating whether the generated situation-aware video can be accurately translated into the correct control signals in dynamic environments.
Our comprehensive evaluation offers key insights that can drive further innovation in video generation models, positioning World Simulators as a pivotal advancement toward embodied artificial intelligence.
5. Image Segmentation
5.1. SAM2Long: Enhancing SAM 2 for Long Video Segmentation with a Training-Free Memory Tree

The Segment Anything Model 2 (SAM 2) has emerged as a powerful foundation model for object segmentation in both images and videos, paving the way for various downstream video applications.
The crucial design of SAM 2 for video segmentation is its memory module, which prompts object-aware memories from previous frames for current frame prediction.
However, its greedy-selection memory design suffers from the “error accumulation” problem, where an errored or missed mask will cascade and influence the segmentation of the subsequent frames, which limits the performance of SAM 2 toward complex long-term videos.
To this end, we introduce SAM2Long, an improved training-free video object segmentation strategy, which considers the segmentation uncertainty within each frame and chooses the video-level optimal results from multiple segmentation pathways in a constrained tree search manner.
In practice, we maintain a fixed number of segmentation pathways throughout the video. For each frame, multiple masks are proposed based on the existing pathways, creating various candidate branches. We then select the same fixed number of branches with higher cumulative scores as the new pathways for the next frame.
After processing the final frame, the pathway with the highest cumulative score is chosen as the final segmentation result. Benefiting from its heuristic search design, SAM2Long is robust toward occlusions and object reappearances, and can effectively segment and track objects for complex long-term videos.
Notably, SAM2Long achieves an average improvement of 3.0 points across all 24 head-to-head comparisons, with gains of up to 5.3 points in J&F on long-term video object segmentation benchmarks such as SA-V and LVOS.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
