


Important Computer Vision Papers for the Week from 28/10 to 03/11
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fifth Week of October 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Image Generation & Editing
Video Generation & Editing
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. FasterCache: Training-Free Video Diffusion Model Acceleration with High-Quality

In this paper, we present \textit{FasterCache}, a novel training-free strategy designed to accelerate the inference of video diffusion models with high-quality generation.
By analyzing existing cache-based methods, we observe that directly reusing adjacent-step features degrades video quality due to the loss of subtle variations.
We further perform a pioneering investigation of the acceleration potential of classifier-free guidance (CFG) and reveal significant redundancy between conditional and unconditional features within the same timestep.
Capitalizing on these observations, we introduce FasterCache to substantially accelerate diffusion-based video generation. Our key contributions include a dynamic feature reuse strategy that preserves both feature distinction and temporal continuity and CFG-Cache which optimizes the reuse of conditional and unconditional outputs to further enhance inference speed without compromising video quality.
We empirically evaluate FasterCache on recent video diffusion models. Experimental results show that FasterCache can significantly accelerate video generation (\eg 1.67times speedup on Vchitect-2.0) while keeping video quality comparable to the baseline, and consistently outperforming existing methods in both inference speed and video quality.
1.2. GrounDiT: Grounding Diffusion Transformers via Noisy Patch Transplantation

We introduce a novel training-free spatial grounding technique for text-to-image generation using Diffusion Transformers (DiT). Spatial grounding with bounding boxes has gained attention for its simplicity and versatility, allowing for enhanced user control in image generation.
However, prior training-free approaches often rely on updating the noisy image during the reverse diffusion process via backpropagation from custom loss functions, which frequently struggle to provide precise control over individual bounding boxes.
In this work, we leverage the flexibility of the Transformer architecture, demonstrating that DiT can generate noisy patches corresponding to each bounding box, fully encoding the target object and allowing for fine-grained control over each region.
Our approach builds on an intriguing property of DiT, which we refer to as semantic sharing. Due to semantic sharing, when a smaller patch is jointly denoised alongside a generatable-size image, the two become “semantic clones”.
Each patch is denoised in its own branch of the generation process and then transplanted into the corresponding region of the original noisy image at each timestep, resulting in robust spatial grounding for each bounding box.
In our experiments on the HRS and DrawBench benchmarks, we achieve state-of-the-art performance compared to previous training-free spatial grounding approaches.
2. Image Generation & Editing
2.1. Unpacking SDXL Turbo: Interpreting Text-to-Image Models with Sparse Autoencoders

Sparse autoencoders (SAEs) have become a core ingredient in the reverse engineering of large-language models (LLMs). For LLMs, they have been shown to decompose intermediate representations that often are not interpretable directly into sparse sums of interpretable features, facilitating better control and subsequent analysis.
However, similar analyses and approaches have been lacking for text-to-image models. We investigated the possibility of using SAEs to learn interpretable features for a few-step text-to-image diffusion models, such as SDXL Turbo.
To this end, we train SAEs on the updates performed by transformer blocks within SDXL Turbo’s denoising U-net. We find that their learned features are interpretable, causally influence the generation process, and reveal specialization among the blocks.
In particular, we find one block that deals mainly with image composition, one that is mainly responsible for adding local details, and one for color, illumination, and style.
Therefore, our work is an important first step towards better understanding the internals of generative text-to-image models like SDXL Turbo and showcases the potential of features learned by SAEs for the visual domain.
3. Video Generation & Editing
3.1. SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation

Human beings are endowed with a complementary learning system, which bridges the slow learning of general world dynamics with fast storage of episodic memory from a new experience.
Previous video generation models, however, primarily focus on slow learning by pre-training on vast amounts of data, overlooking the fast learning phase crucial for episodic memory storage.
This oversight leads to inconsistencies across temporally distant frames when generating longer videos, as these frames fall beyond the model’s context window.
To this end, we introduce SlowFast-VGen, a novel dual-speed learning system for action-driven long video generation. Our approach incorporates a masked conditional video diffusion model for the slow learning of world dynamics, alongside an inference-time fast learning strategy based on a temporal LoRA module.
Specifically, the fast learning process updates its temporal LoRA parameters based on local inputs and outputs, thereby efficiently storing episodic memory in its parameters.
We further propose a slow-fast learning loop algorithm that seamlessly integrates the inner fast learning loop into the outer slow learning loop, enabling the recall of prior multi-episode experiences for context-aware skill learning.
To facilitate the slow learning of an approximate world model, we collect a large-scale dataset of 200k videos with language action annotations, covering a wide range of scenarios.
Extensive experiments show that SlowFast-VGen outperforms baselines across various metrics for action-driven video generation, achieving an FVD score of 514 compared to 782, and maintaining consistency in longer videos, with an average of 0.37 scene cuts versus 0.89. The slow-fast learning loop algorithm significantly enhances performances on long-horizon planning tasks as well.
3.2. DELTA: Dense Efficient Long-range 3D Tracking for any video
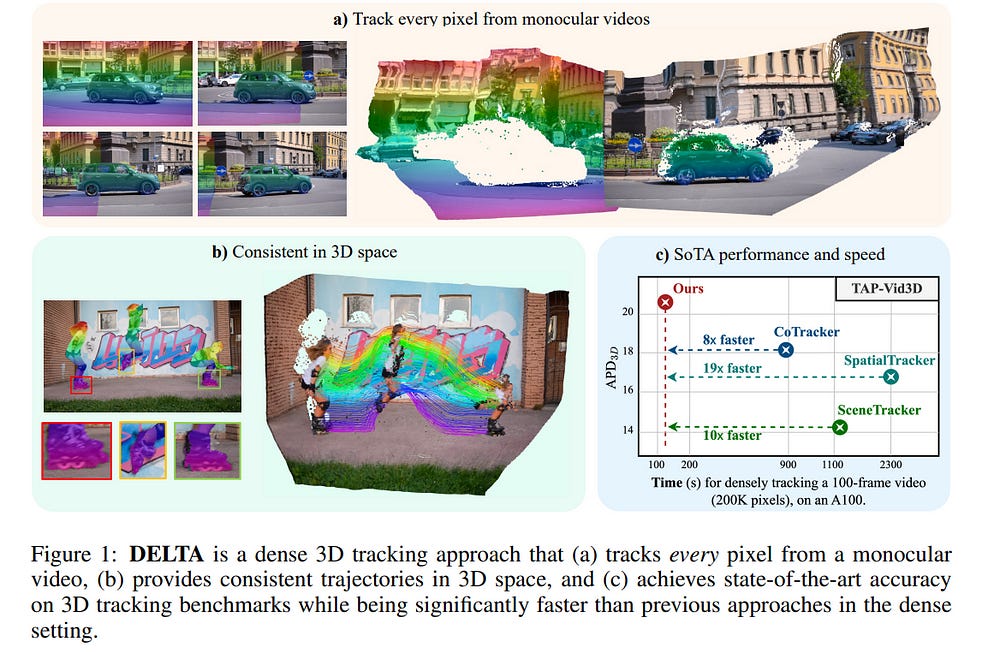
Tracking dense 3D motion from monocular videos remains challenging, particularly when aiming for pixel-level precision over long sequences. We introduce \Approach, a novel method that efficiently tracks every pixel in 3D space, enabling accurate motion estimation across entire videos.
Our approach leverages a joint global-local attention mechanism for reduced-resolution tracking, followed by a transformer-based upsampler to achieve high-resolution predictions.
Unlike existing methods, which are limited by computational inefficiency or sparse tracking, \Approach delivers dense 3D tracking at scale, running over 8x faster than previous methods while achieving state-of-the-art accuracy.
Furthermore, we explore the impact of depth representation on tracking performance and identify log-depth as the optimal choice. Extensive experiments demonstrate the superiority of \Approach on multiple benchmarks, achieving new state-of-the-art results in both 2D and 3D dense tracking tasks. Our method provides a robust solution for applications requiring fine-grained, long-term motion tracking in 3D space.
4. Image Segmentation
4.1. ReferEverything: Towards Segmenting Everything We Can Speak of in Videos

We present REM, a framework for segmenting a wide range of concepts in video that can be described through natural language. Our method capitalizes on visual-language representations learned by video diffusion models on Internet-scale datasets.
A key insight of our approach is preserving as much of the generative model’s original representation as possible while fine-tuning it on narrow-domain Referral Object Segmentation datasets. As a result, our framework can accurately segment and track rare and unseen objects, despite being trained on object masks from a limited set of categories.
Additionally, it can generalize to non-object dynamic concepts, such as waves crashing in the ocean, as demonstrated in our newly introduced benchmark for Referral Video Process Segmentation (Ref-VPS).
Our experiments show that REM performs on par with state-of-the-art approaches on in-domain datasets, like Ref-DAVIS, while outperforming them by up to twelve points in terms of region similarity on out-of-domain data, leveraging the power of Internet-scale pre-training.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
