
Important Computer Vision Papers for the Week from 30/12 to 05/01
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First week of January 2025, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Text to Image Generation
3D Image Generation & Editing
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. Diffusion Models
1.1. VMix: Improving Text-to-Image Diffusion Model with Cross-Attention Mixing Control

While diffusion models show extraordinary talents in text-to-image generation, they may still fail to generate highly aesthetic images. More specifically, there is still a gap between the generated images and the real-world aesthetic images in finer-grained dimensions including color, lighting, composition, etc.
In this paper, we propose Cross-Attention Value Mixing Control (VMix) Adapter, a plug-and-play aesthetics adapter, to upgrade the quality of generated images while maintaining generality across visual concepts by:
Disentangling the input text prompt into the content description and aesthetic description by the initialization of aesthetic embedding.
Integrating aesthetic conditions into the denoising process through value-mixed cross-attention, with the network connected by zero-initialized linear layers.
Our key insight is to enhance the aesthetic presentation of existing diffusion models by designing a superior condition control method, all while preserving the image-text alignment. Through our meticulous design, VMix is flexible enough to be applied to community models for better visual performance without retraining.
To validate the effectiveness of our method, we conducted extensive experiments. These showed that VMix outperforms other state-of-the-art methods and is compatible with other community modules (e.g., LoRA, ControlNet, and IPAdapter) for image generation.
2. Vision Language Models
2.1. Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment

Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications.
Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance.
To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks.
TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM’s multimodal capabilities and task-specific performance.
Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies.
Our instantiation of this approach with video chat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models.
2.2. Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization

Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others.
In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation’’), which may be a key barrier to zero-shot task generalization.
Our hypothesis is that deep models struggle to generalize to novel tasks without truly understanding previously seen tasks, due to these terminological definitions.
To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs.
We create a large-scale dataset comprising 12 million ``image inputs to explanatory instruction to output’’ triplets and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input.
By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
2.3. years in Class: A Multimodal Textbook for Vision-Language Pretraining

Compared to image-text pair data, interleaved corpora enable Vision-Language Models (VLMs) to understand the world more naturally like humans.
However, such existing datasets are crawled from web pages, facing challenges like low knowledge density, loose image-text relations, and poor logical coherence between images.
On the other hand, the internet hosts vast instructional videos (e.g., online geometry courses) that are widely used by humans to learn foundational subjects, yet these valuable resources remain underexplored in VLM training.
In this paper, we introduce a high-quality multimodal textbook corpus with richer foundational knowledge for VLM pretraining. It collects over 2.5 years of instructional videos, totaling 22,000 class hours.
We first use an LLM-proposed taxonomy to systematically gather instructional videos. Then we progressively extract and refine visual (keyframes), audio (ASR), and textual knowledge (OCR) from the videos, and organize them as an image-text interleaved corpus based on temporal order.
Compared to its counterparts, our video-centric textbook offers more coherent context, richer knowledge, and better image-text alignment. Experiments demonstrate its superb pretraining performance, particularly in knowledge- and reasoning-intensive tasks like ScienceQA and MathVista.
Moreover, VLMs pre-trained on our textbook exhibit outstanding interleaved context awareness, leveraging visual and textual cues in their few-shot context to solve tasks.
2.4. Are Vision-Language Models Truly Understanding Multi-vision Sensors?

Large-scale Vision-Language Models (VLMs) have advanced by aligning vision inputs with text, significantly improving performance in computer vision tasks.
Moreover, for VLMs to be effectively utilized in real-world applications, an understanding of diverse multi-vision sensor data, such as thermal, depth, and X-ray information, is essential. However, we find that current VLMs process multi-vision sensor images without a deep understanding of sensor information, disregarding each sensor’s unique physical properties.
This limitation restricts their capacity to interpret and respond to complex questions requiring multi-vision sensor reasoning. To address this, we propose a novel Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark, assessing VLMs on their capacity for sensor-specific reasoning.
Moreover, we introduce Diverse Negative Attributes (DNA) optimization to enable VLMs to perform deep reasoning on multi-vision sensor tasks, helping to bridge the core information gap between images and sensor data. Extensive experimental results validate that the proposed DNA method can significantly improve the multi-vision sensor reasoning for VLMs.
2.5. MLLM-as-a-Judge for Image Safety without Human Labeling

Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image-generation models are capable of producing harmful content, such as images containing sexual or violent material.
Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities.
Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive.
Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)?
Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models.
To address these challenges, we propose a MLLM-based method that includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary.
Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
3. Video Generation & Editing
3.1. LTX-Video: Realtime Video Latent Diffusion

We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer.
Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality.
At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the pacifying operation from the transformer’s input to the VAE’s input.
Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency.
However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space.
This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously.
It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale.
The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation.
3.2. VideoRefer Suite: Advancing Spatial-Temporal Object Understanding with Video LLM
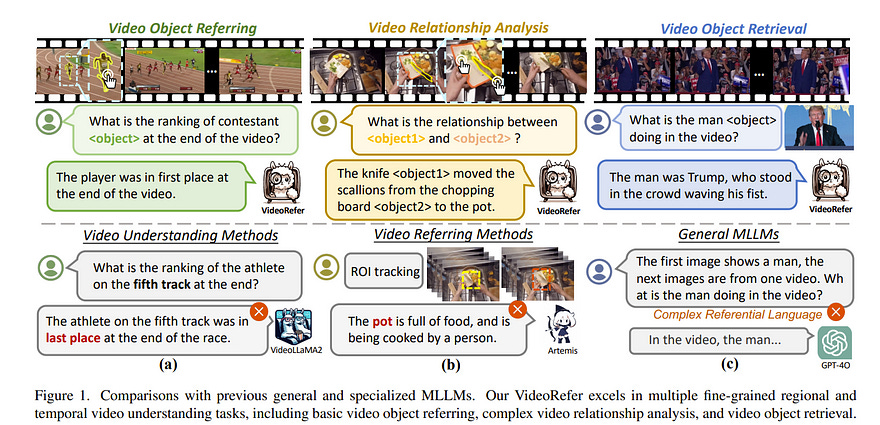
Video Large Language Models (Video LLMs) have recently exhibited remarkable capabilities in general video understanding. However, they mainly focus on holistic comprehension and struggle with capturing fine-grained spatial and temporal details.
Besides, the lack of high-quality object-level video instruction data and a comprehensive benchmark further hinders their advancements. To tackle these challenges, we introduce the VideoRefer Suite to empower Video LLM for finer-level spatial-temporal video understanding, i.e., enabling perception and reasoning on any objects throughout the video.
In particular, we thoroughly develop VideoRefer Suite across three essential aspects: dataset, model, and benchmark. Firstly, we introduce a multi-agent data engine to meticulously curate a large-scale, high-quality object-level video instruction dataset, termed VideoRefer-700K.
Next, we present the VideoRefer model, which equips a versatile spatial-temporal object encoder to capture precise regional and sequential representations.
Finally, we meticulously create a VideoRefer-Bench to comprehensively assess the spatial-temporal understanding capability of a Video LLM, evaluating it across various aspects.
Extensive experiments and analyses demonstrate that our VideoRefer model not only achieves promising performance on video-referring benchmarks but also facilitates general video understanding capabilities.
3.3. VideoAnydoor: High-fidelity Video Object Insertion with Precise Motion Control

Despite significant advancements in video generation, inserting a given object into videos remains a challenging task. The difficulty lies in preserving the appearance details of the reference object and accurately modeling coherent motions at the same time.
In this paper, we propose VideoAnydoor, a zero-shot video object insertion framework with high-fidelity detail preservation and precise motion control. Starting from a text-to-video model, we utilize an ID extractor to inject the global identity and leverage a box sequence to control the overall motion.
We design a pixel warper to preserve the detailed appearance and support fine-grained motion control. It takes the reference image with arbitrary key points and the corresponding key point trajectories as inputs.
It warps the pixel details according to the trajectories and fuses the warped features with the diffusion U-Net, thus improving detail preservation and supporting users in manipulating the motion trajectories.
In addition, we propose a training strategy involving both videos and static images with a reweight reconstruction loss to enhance insertion quality. VideoAnydoor demonstrates significant superiority over existing methods and naturally supports various downstream applications (e.g., talking head generation, video virtual try-on, multi-region editing) without task-specific fine-tuning.
4. Text to Image Generation & Editing
4.1. Edicho: Consistent Image Editing in the Wild

As a verified need, consistent editing across in-the-wild images remains a technical challenge arising from various unmanageable factors, like object poses, lighting conditions, and photography environments.
Edicho steps in with a training-free solution based on diffusion models, featuring a fundamental design principle of using explicit image correspondence to direct editing.
Specifically, the key components include an attention manipulation module and a carefully refined classifier-free guidance (CFG) denoising strategy, both of which take into account the pre-estimated correspondence. Such an inference-time algorithm enjoys a plug-and-play nature and is compatible with most diffusion-based editing methods, such as ControlNet and BrushNet.
Extensive results demonstrate the efficacy of Edicho in consistent cross-image editing under diverse settings. We will release the code to facilitate future studies.
5. 3D Image Generation
5.1 Orient Anything: Learning Robust Object Orientation Estimation from Rendering 3D Models

Orientation is a key attribute of objects, crucial for understanding their spatial pose and arrangement in images. However, practical solutions for accurate orientation estimation from a single image remain underexplored.
In this work, we introduce Orient Anything, the first expert and foundational model designed to estimate object orientation in a single- and free-view image. Due to the scarcity of labeled data, we propose extracting knowledge from the 3D world.
By developing a pipeline to annotate the front face of 3D objects and render images from random views, we collect 2M images with precise orientation annotations.
To fully leverage the dataset, we design a robust training objective that models the 3D orientation as probability distributions of three angles and predicts the object orientation by fitting these distributions. Besides, we employ several strategies to improve synthetic-to-real transfer.
Our model achieves state-of-the-art orientation estimation accuracy in both rendered and real images and exhibits impressive zero-shot ability in various scenarios.
More importantly, our model enhances many applications, such as comprehension and generation of complex spatial concepts and 3D object pose adjustment.
5.2. PERSE: Personalized 3D Generative Avatars from A Single Portrait

We present PERSE, a method for building an animatable personalized generative avatar from a reference portrait. Our avatar model enables facial attribute editing in a continuous and disentangled latent space to control each facial attribute while preserving the individual’s identity.
To achieve this, our method begins by synthesizing large-scale synthetic 2D video datasets, where each video contains consistent changes in the facial expression and viewpoint, combined with a variation in a specific facial attribute from the original input.
We propose a novel pipeline to produce high-quality, photorealistic 2D videos with facial attribute editing. Leveraging this synthetic attribute dataset, we present a personalized avatar creation method based on the 3D Gaussian Splatting, learning a continuous and disentangled latent space for intuitive facial attribute manipulation.
To enforce smooth transitions in this latent space, we introduce a latent space regularization technique by using interpolated 2D faces as supervision. Compared to previous approaches, we demonstrate that PERSE generates high-quality avatars with interpolated attributes while preserving the identity of the reference person.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
