


Important Computer Vision Papers for the Week from 18/11 to 24/11
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of November 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Vision Language Models
Video Generation & Editing
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Vision Language Models
1.1. LLaVA-o1: Let Vision Language Models Reason Step-by-Step

Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI’s o1.
However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-o1, a novel VLM designed to conduct autonomous multistage reasoning.
Unlike chain-of-thought prompting, LLaVA-o1 independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-o1 to achieve marked improvements in precision on reasoning-intensive tasks.
To accomplish this, we compile the LLaVA-o1–100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling.
Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-o1 not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2–90B-Vision-Instruct.
2. Video Generation & Editing
2.1. AnimateAnything: Consistent and Controllable Animation for Video Generation

We present a unified controllable video generation approach AnimateAnything that facilitates precise and consistent video manipulation across various conditions, including camera trajectories, text prompts, and user motion annotations.
Specifically, we carefully design a multi-scale control feature fusion network to construct a common motion representation for different conditions. It explicitly converts all control information into frame-by-frame optical flows. Then we incorporate the optical flows as motion priors to guide final video generation.
In addition, to reduce the flickering issues caused by large-scale motion, we propose a frequency-based stabilization module. It can enhance temporal coherence by ensuring the video’s frequency domain consistency. Experiments demonstrate that our method outperforms the state-of-the-art approaches.
2.2. FlipSketch: Flipping Static Drawings to Text-Guided Sketch Animations

Sketch animations offer a powerful medium for visual storytelling, from simple flip-book doodles to professional studio productions. While traditional animation requires teams of skilled artists to draw key frames and in-between frames, existing automation attempts still demand significant artistic effort through precise motion paths or keyframe specifications.
We present FlipSketch, a system that brings back the magic of flip-book animation — just draw your idea and describe how you want it to move! Our approach harnesses motion priors from text-to-video diffusion models, adapting them to generate sketch animations through three key innovations: (i) fine-tuning for sketch-style frame generation, (ii) a reference frame mechanism that preserves visual integrity of input sketch through noise refinement, and (iii) a dual-attention composition that enables fluid motion without losing visual consistency.
Unlike constrained vector animations, our raster frames support dynamic sketch transformations, capturing the expressive freedom of traditional animation. The result is an intuitive system that makes sketch animation as simple as doodling and describing while maintaining the artistic essence of hand-drawn animation.
2.3. VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models

Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation.
To this end, we present VBench, a comprehensive benchmark suite that dissects “video generation quality” into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods.
VBench has several appealing properties:
Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models’ strengths and weaknesses.
Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks’ alignment with human perception, for each evaluation dimension respectively.
Valuable Insights: We look into current models’ ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models.
Versatile Benchmarking: VBench++ supports evaluating text-to-video and image-to-video. We introduce a high-quality Image Suite with an adaptive aspect ratio to enable fair evaluations across different image-to-video generation settings. Beyond assessing technical quality, VBench++ evaluates the trustworthiness of video generative models, providing a more holistic view of model performance.
Full Open-Sourcing: We fully open-source VBench++ and continually add new video generation models to our leaderboard to drive forward the field of video generation.
2.4. VideoAutoArena: An Automated Arena for Evaluating Large Multimodal Models in Video Analysis through User Simulation

Large multimodal models (LMMs) with advanced video analysis capabilities have recently garnered significant attention. However, most evaluations rely on traditional methods like multiple-choice questions in benchmarks such as VideoMME and LongVideoBench, which are prone to lack the depth needed to capture the complex demands of real-world users.
To address this limitation-and due to the prohibitive cost and slow pace of human annotation for video tasks, we introduce VideoAutoArena, an arena-style benchmark inspired by LMSYS Chatbot Arena’s framework, designed to automatically assess LMMs’ video analysis abilities.
VideoAutoArena utilizes user simulation to generate open-ended, adaptive questions that rigorously assess model performance in video understanding. The benchmark features an automated, scalable evaluation framework, incorporating a modified ELO Rating System for fair and continuous comparisons across multiple LMMs.
To validate our automated judging system, we construct a ‘gold standard’ using a carefully curated subset of human annotations, demonstrating that our arena strongly aligns with human judgment while maintaining scalability. Additionally, we introduce a fault-driven evolution strategy, progressively increasing question complexity to push models toward handling more challenging video analysis scenarios.
Experimental results demonstrate that VideoAutoArena effectively differentiates among state-of-the-art LMMs, providing insights into model strengths and areas for improvement. To further streamline our evaluation, we introduce VideoAutoBench as an auxiliary benchmark, where human annotators label winners in a subset of VideoAutoArena battles.
We use GPT-4o as a judge to compare responses against these human-validated answers. Together, VideoAutoArena and VideoAutoBench offer a cost-effective, and scalable framework for evaluating LMMs in user-centric video analysis.
2.5. MagicDriveDiT: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control
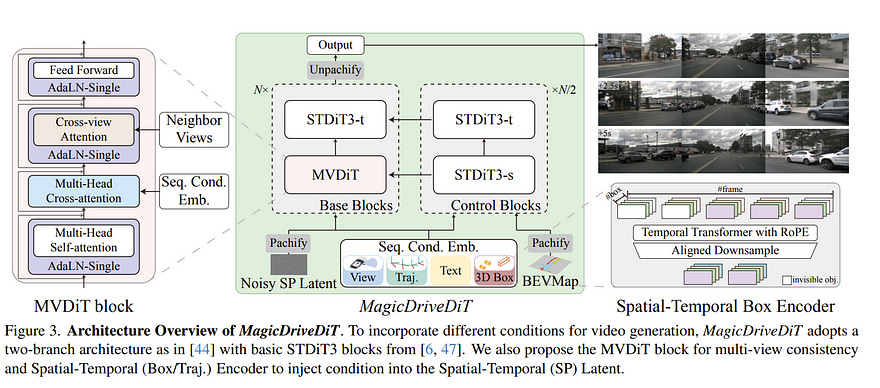
The rapid advancement of diffusion models has greatly improved video synthesis, especially in controllable video generation, which is essential for applications like autonomous driving.
However, existing methods are limited by scalability and how control conditions are integrated, failing to meet the needs for high-resolution and long videos for autonomous driving applications.
In this paper, we introduce MagicDriveDiT, a novel approach based on the DiT architecture, and tackle these challenges. Our method enhances scalability through flow matching and employs a progressive training strategy to manage complex scenarios.
By incorporating spatial-temporal conditional encoding, MagicDriveDiT achieves precise control over spatial-temporal latents. Comprehensive experiments show its superior performance in generating realistic street scene videos with higher resolution and more frames.
MagicDriveDiT significantly improves video generation quality and spatial-temporal controls, expanding its potential applications across various tasks in autonomous driving.
3. Image Segmentation
3.1. SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory

The Segment Anything Model 2 (SAM 2) has demonstrated strong performance in object segmentation tasks but faces challenges in visual object tracking, particularly when managing crowded scenes with fast-moving or self-occluding objects.
Furthermore, the fixed-window memory approach in the original model does not consider the quality of memories selected to condition the image features for the next frame, leading to error propagation in videos. This paper introduces SAMURAI, an enhanced adaptation of SAM 2 specifically designed for visual object tracking.
By incorporating temporal motion cues with the proposed motion-aware memory selection mechanism, SAMURAI effectively predicts object motion and refines mask selection, achieving robust, accurate tracking without the need for retraining or fine-tuning.
SAMURAI operates in real-time and demonstrates strong zero-shot performance across diverse benchmark datasets, showcasing its ability to generalize without fine-tuning.
In evaluations, SAMURAI achieves significant improvements in success rate and precision over existing trackers, with a 7.1% AUC gain on LaSOT_{ext} and a 3.5% AO gain on GOT-10k.
Moreover, it achieves competitive results compared to fully supervised methods on LaSOT, underscoring its robustness in complex tracking scenarios and its potential for real-world applications in dynamic environments.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
