


Important Computer Vision Papers for the Week from 06/01 to 12/01
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Second week of January 2025, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Text to Image Generation

1. Diffusion Models
1.1. Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control

Diffusion models have demonstrated impressive performance in generating high-quality videos from text prompts or images. However, precise control over the video generation process, such as camera manipulation or content editing, remains a significant challenge.
Existing methods for controlled video generation are typically limited to a single control type, lacking the flexibility to handle diverse control demands.
In this paper, we introduce Diffusion as Shader (DaS), a novel approach that supports multiple video control tasks within a unified architecture. Our key insight is that achieving versatile video control necessitates leveraging 3D control signals, as videos are fundamentally 2D renderings of dynamic 3D content.
Unlike prior methods limited to 2D control signals, DaS leverages 3D tracking videos as control inputs, making the video diffusion process inherently 3D-aware.
This innovation allows DaS to achieve a wide range of video controls by simply manipulating the 3D tracking videos. A further advantage of using 3D tracking videos is their ability to effectively link frames, significantly enhancing the temporal consistency of the generated videos.
With just 3 days of fine-tuning on 8 H800 GPUs using less than 10k videos, DaS demonstrates strong control capabilities across diverse tasks, including mesh-to-video generation, camera control, motion transfer, and object manipulation.
2. Vision Language Models
2.1. LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
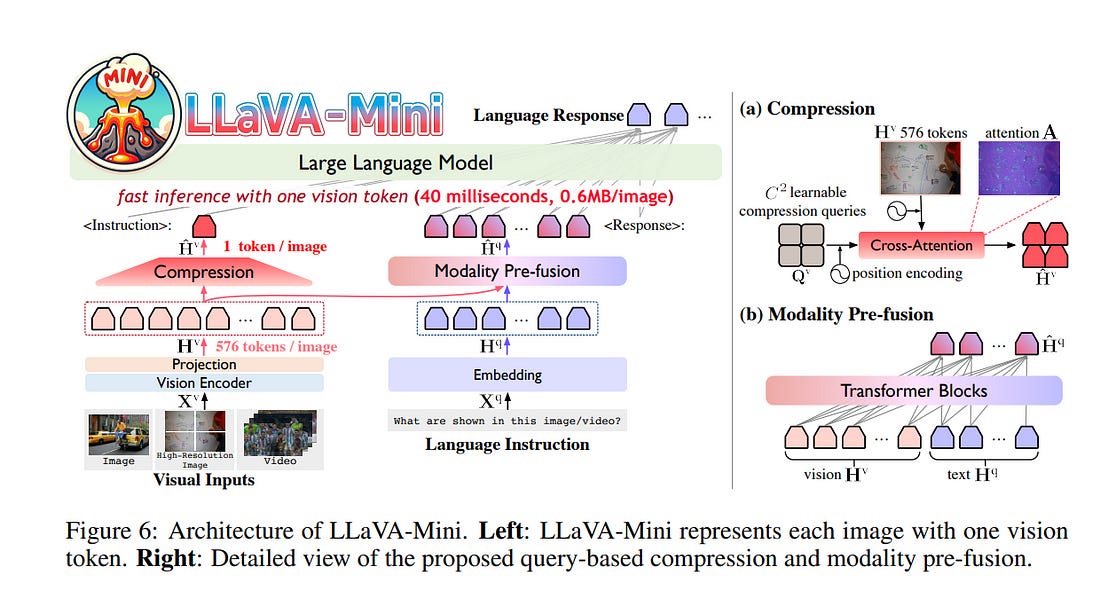
The advent of real-time large multimodal models (LMMs) like GPT-4o has sparked considerable interest in efficient LMMs. LMM frameworks typically encode visual inputs into vision tokens (continuous representations) and integrate them and textual instructions into the context of large language models (LLMs), where large-scale parameters and numerous context tokens (predominantly vision tokens) result in substantial computational overhead.
Previous efforts towards efficient LMMs always focus on replacing the LLM backbone with smaller models, while neglecting the crucial issue of token quantity. In this paper, we introduce LLaVA-Mini, an efficient LMM with minimal vision tokens.
To achieve a high compression ratio of vision tokens while preserving visual information, we first analyze how LMMs understand vision tokens and find that most vision tokens only play a crucial role in the early layers of the LLM backbone, where they mainly fuse visual information into text tokens.
Building on this finding, LLaVA-Mini introduces modality pre-fusion to fuse visual information into text tokens in advance, thereby facilitating the extreme compression of vision tokens fed to the LLM backbone into one token.
LLaVA-Mini is a unified large multimodal model that can support the understanding of images, high-resolution images, and videos in an efficient manner.
Experiments across 11 image-based and 7 video-based benchmarks demonstrate that LLaVA-Mini outperforms LLaVA-v1.5 with just 1 vision token instead of 576.
Efficiency analyses reveal that LLaVA-Mini can reduce FLOPs by 77%, deliver low-latency responses within 40 milliseconds, and process over 10,000 frames of video on GPU hardware with 24GB of memory.
2.2. Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos

This work presents Sa2VA, the first unified model for a dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning.
Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space.
Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content.
Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance.
We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
2.3. Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
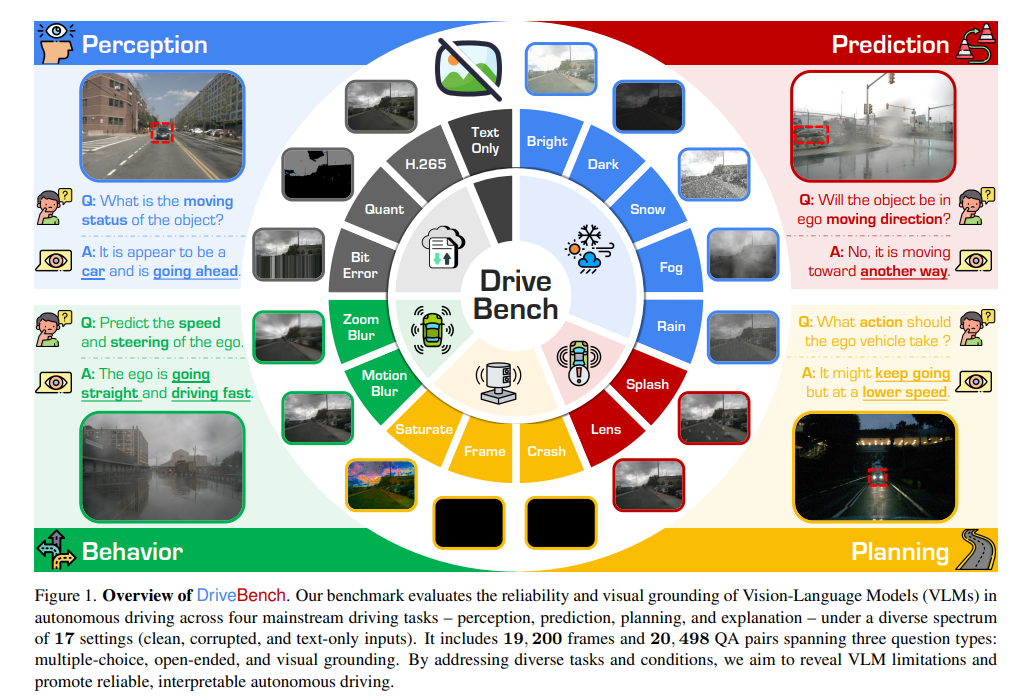
Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language.
However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined.
To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs.
Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs.
This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance.
To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs’ awareness of corruption to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
3. Video Generation & Editing
3.1. STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution

Image diffusion models have been adapted for real-world video super-resolution to tackle over-smoothing issues in GAN-based methods. However, these models struggle to maintain temporal consistency, as they are trained on static images, limiting their ability to capture temporal dynamics effectively.
Integrating text-to-video (T2V) models into video super-resolution for improved temporal modeling is straightforward. However, two key challenges remain: artifacts introduced by complex degradations in real-world scenarios, and compromised fidelity due to the strong generative capacity of powerful T2V models (e.g., CogVideoX-5B).
To enhance the spatio-temporal quality of restored videos, we introduce~\name (Spatial-Temporal Augmentation with T2V models for Real-world video super-resolution), a novel approach that leverages T2V models for real-world video super-resolution, achieving realistic spatial details and robust temporal consistency.
Specifically, we introduce a Local Information Enhancement Module (LIEM) before the global attention block to enrich local details and mitigate degradation artifacts.
Moreover, we propose a Dynamic Frequency (DF) Loss to reinforce fidelity, guiding the model to focus on different frequency components across diffusion steps. Extensive experiments demonstrate~\name~outperforms state-of-the-art methods on both synthetic and real-world datasets.
3.2. TransPixar: Advancing Text-to-Video Generation with Transparency

Text-to-video generative models have made significant strides, enabling diverse applications in entertainment, advertising, and education. However, generating RGBA video, which includes alpha channels for transparency, remains a challenge due to limited datasets and the difficulty of adapting existing models.
Alpha channels are crucial for visual effects (VFX), allowing transparent elements like smoke and reflections to blend seamlessly into scenes. We introduce TransPixar, a method to extend pretrained video models for RGBA generation while retaining the original RGB capabilities.
TransPixar leverages a diffusion transformer (DiT) architecture, incorporating alpha-specific tokens and using LoRA-based fine-tuning to jointly generate RGB and alpha channels with high consistency.
By optimizing attention mechanisms, TransPixar preserves the strengths of the original RGB model and achieves strong alignment between RGB and alpha channels despite limited training data. Our approach effectively generates diverse and consistent RGBA videos, advancing the possibilities for VFX and interactive content creation.
3.3. Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction

Active Real-time interaction with video LLMs introduces a new paradigm for human-computer interaction, where the model not only understands user intent but also responds while continuously processing streaming video on the fly.
Unlike offline video LLMs, which analyze the entire video before answering questions, active real-time interaction requires three capabilities:
Perception: real-time video monitoring and interaction capturing.
Decision: raising proactive interaction in proper situations.
Reaction: continuous interaction with users.
However, inherent conflicts exist among the desired capabilities. The Decision and Reaction require a contrary Perception scale and grain, and the autoregressive decoding blocks the real-time Perception and Decision during the Reaction.
To unify the conflicted capabilities within a harmonious system, we present Dispider, a system that disentangles Perception, Decision, and Reaction.
Dispider features a lightweight proactive streaming video processing module that tracks the video stream and identifies optimal moments for interaction.
Once the interaction is triggered, an asynchronous interaction module provides detailed responses, while the processing module continues to monitor the video in the meantime.
Our disentangled and asynchronous design ensures timely, contextually accurate, and computationally efficient responses, making Dispider ideal for active real-time interaction for long-duration video streams.
Experiments show that Dispider not only maintains strong performance in conventional video QA tasks but also significantly surpasses previous online models in streaming scenario responses, thereby validating the effectiveness of our architecture.
4. Text to Image Generation
4.1. VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation

We present a general strategy for aligning visual generation models — both image and video generation — with human preference. First, we build VisionReward — a fine-grained and multi-dimensional reward model.
We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score.
To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction.
Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
