


Important Computer Vision Papers for the Week from 25/11 to 30/11
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of November 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. OminiControl: Minimal and Universal Control for Diffusion Transformer

In this paper, we introduce OminiControl, a highly versatile and parameter-efficient framework that integrates image conditions into pre-trained Diffusion Transformer (DiT) models.
At its core, OminiControl leverages a parameter reuse mechanism, enabling the DiT to encode image conditions using itself as a powerful backbone and process them with its flexible multi-modal attention processors.
Unlike existing methods, which rely heavily on additional encoder modules with complex architectures, OminiControl (1) effectively and efficiently incorporates injected image conditions with only ~0.1% additional parameters, and (2) addresses a wide range of image conditioning tasks in a unified manner, including subject-driven generation and spatially-aligned conditions such as edges, depth, and more.
Remarkably, these capabilities are achieved by training on images generated by the DiT itself, which is particularly beneficial for subject-driven generation.
Extensive evaluations demonstrate that OminiControl outperforms existing UNet-based and DiT-adapted models in both subject-driven and spatially-aligned conditional generation.
Additionally, we release our training dataset, Subjects200K, a diverse collection of over 200,000 identity-consistent images, along with an efficient data synthesis pipeline to advance research in subject-consistent generation.
1.2. Material Anything: Generating Materials for Any 3D Object via Diffusion

We present Material Anything, a fully automated, unified diffusion framework designed to generate physically based materials for 3D objects. Unlike existing methods that rely on complex pipelines or case-specific optimizations, Material Anything offers a robust, end-to-end solution adaptable to objects under diverse lighting conditions.
Our approach leverages a pre-trained image diffusion model, enhanced with a triple-head architecture and rendering loss to improve stability and material quality.
Additionally, we introduce confidence masks as a dynamic switcher within the diffusion model, enabling it to effectively handle both textured and texture-less objects across varying lighting conditions.
By employing a progressive material generation strategy guided by these confidence masks, along with a UV-space material refiner, our method ensures consistent, UV-ready material outputs.
Extensive experiments demonstrate our approach outperforms existing methods across a wide range of object categories and lighting conditions.
1.3. One Diffusion to Generate Them All

We introduce OneDiffusion, a versatile, large-scale diffusion model that seamlessly supports bidirectional image synthesis and understanding across diverse tasks.
It enables conditional generation from inputs such as text, depth, pose, layout, and semantic maps, while also handling tasks like image deblurring, upscaling, and reverse processes such as depth estimation and segmentation.
Additionally, OneDiffusion allows for multi-view generation, camera pose estimation, and instant personalization using sequential image inputs. Our model takes a straightforward yet effective approach by treating all tasks as frame sequences with varying noise scales during training, allowing any frame to act as a conditioning image at inference time.
Our unified training framework removes the need for specialized architectures, supports scalable multi-task training, and adapts smoothly to any resolution, enhancing both generalization and scalability.
Experimental results demonstrate competitive performance across tasks in both generation and prediction such as text-to-image, multiview generation, ID preservation, depth estimation, and camera pose estimation despite a relatively small training dataset.
1.4. Diffusion Self-Distillation for Zero-Shot Customized Image Generation

Text-to-image diffusion models produce impressive results but are frustrating tools for artists who desire fine-grained control. For example, a common use case is to create images of a specific instance in novel contexts, i.e., “identity-preserving generation”.
This setting, along with many other tasks (e.g., relighting), is a natural fit for image+text-conditional generative models. However, there is insufficient high-quality paired data to train such a model directly.
We propose Diffusion Self-Distillation, a method for using a pre-trained text-to-image model to generate its own dataset for text-conditioned image-to-image tasks.
We first leverage a text-to-image diffusion model’s in-context generation ability to create grids of images and curate a large paired dataset with the help of a Visual-Language Model.
We then fine-tune the text-to-image model into a text+image-to-image model using the curated paired dataset. We demonstrate that Diffusion Self-Distillation outperforms existing zero-shot methods and is competitive with per-instance tuning techniques on a wide range of identity-preservation generation tasks, without requiring test-time optimization.
1.5. DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving

Recently, the diffusion model has emerged as a powerful generative technique for robotic policy learning, capable of modeling multi-mode action distributions.
Leveraging its capability for end-to-end autonomous driving is a promising direction. However, the numerous denoising steps in the robotic diffusion policy and the more dynamic, open-world nature of traffic scenes pose substantial challenges for generating diverse driving actions at a real-time speed.
To address these challenges, we propose a novel truncated diffusion policy that incorporates prior multi-mode anchors and truncates the diffusion schedule, enabling the model to learn denoising from anchored Gaussian distribution to the multi-mode driving action distribution.
Additionally, we design an efficient cascade diffusion decoder for enhanced interaction with conditional scene context. The proposed model, DiffusionDrive, demonstrates a 10 times reduction in denoising steps compared to the vanilla diffusion policy, delivering superior diversity and quality in just 2 steps.
On the planning-oriented NAVSIM dataset, with the aligned ResNet-34 backbone, DiffusionDrive achieves 88.1 PDMS without bells and whistles, setting a new record, while running at a real-time speed of 45 FPS on an NVIDIA 4090.
Qualitative results on challenging scenarios further confirm that DiffusionDrive can robustly generate diverse plausible driving actions.
2. Vision Language Models
2.1. GMAI-VL & GMAI-VL-5.5M: A Large Vision-Language Model and A Comprehensive Multimodal Dataset Towards General Medical AI

Despite significant advancements in general artificial intelligence, such as GPT-4, their effectiveness in the medical domain (general medical AI, GMAI) remains constrained due to the absence of specialized medical knowledge.
To address this challenge, we present GMAI-VL-5.5M, a comprehensive multimodal medical dataset created by converting hundreds of specialized medical datasets into meticulously constructed image-text pairs. This dataset features comprehensive task coverage, diverse modalities, and high-quality image-text data.
Building upon this multimodal dataset, we propose GMAI-VL, a general medical vision-language model with a progressively three-stage training strategy. This approach significantly enhances the model’s ability by integrating visual and textual information, thereby improving its ability to process multimodal data and support accurate diagnosis and clinical decision-making.
Experimental evaluations demonstrate that GMAI-VL achieves state-of-the-art results across a wide range of multimodal medical tasks, such as visual question answering and medical image diagnosis. Our contributions include the development of the GMAI-VL-5.5M dataset, the introduction of the GMAI-VL model, and the establishment of new benchmarks in multiple medical domains.
2.2. ShowUI: One Vision-Language-Action Model for GUI Visual Agent

Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents.
In this work, we develop a vision-language-action model in the digital world, namely ShowUI, which features the following innovations:
UI-guided visual Token Selection to reduce computational costs by formulating screenshots as a UI-connected graph, adaptively identifying their redundant relationship and serving as the criteria for token selection during self-attention blocks;
Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency;
Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances.
With the above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x.
Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents.
2.3. Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning

Vision-language models~(VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths.
To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths.
In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic.
This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner’s capability on complex reasoning tasks.
The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency.
Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process.
Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
3. Video Generation & Editing
3.1. DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation

Storytelling video generation (SVG) has recently emerged as a task to create long, multi-motion, multi-scene videos that consistently represent the story described in the input text script.
SVG holds great potential for diverse content creation in media and entertainment; however, it also presents significant challenges: (1) objects must exhibit a range of fine-grained, complex motions, (2) multiple objects need to appear consistently across scenes, and (3) subjects may require multiple motions with seamless transitions within a single scene.
To address these challenges, we propose DreamRunner, a novel story-to-video generation method: First, we structure the input script using a large language model (LLM) to facilitate both coarse-grained scene planning as well as fine-grained object-level layout and motion planning.
Next, DreamRunner presents retrieval-augmented test-time adaptation to capture target motion priors for objects in each scene, supporting diverse motion customization based on retrieved videos, thus facilitating the generation of new videos with complex, scripted motions.
Lastly, we propose a novel spatial-temporal region-based 3D attention and prior injection module SR3AI for fine-grained object-motion binding and frame-by-frame semantic control.
We compare DreamRunner with various SVG baselines, demonstrating state-of-the-art performance in character consistency, text alignment, and smooth transitions.
Additionally, DreamRunner exhibits strong fine-grained condition-following ability in the compositional text-to-video generation, significantly outperforming baselines on T2V-ComBench. Finally, we validate DreamRunner’s robust ability to generate multi-object interactions with qualitative examples.
3.2. CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models

We present CAT4D, a method for creating 4D (dynamic 3D) scenes from monocular video. CAT4D leverages a multi-view video diffusion model trained on a diverse combination of datasets to enable novel view synthesis at any specified camera pose and timestamps.
Combined with a novel sampling approach, this model can transform a single monocular video into a multi-view video, enabling robust 4D reconstruction via optimization of a deformable 3D Gaussian representation.
We demonstrate competitive performance on novel view synthesis and dynamic scene reconstruction benchmarks and highlight the creative capabilities for 4D scene generation from real or generated videos. See our project page for results and interactive demos: cat-4d.github.io.
4. Image Generation & Editing
4.1. Style-Friendly SNR Sampler for Style-Driven Generation

Recent large-scale diffusion models generate high-quality images but struggle to learn new, personalized artistic styles, which limits the creation of unique style templates.
Fine-tuning with reference images is the most promising approach, but it often blindly utilizes objectives and noise level distributions used for pre-training, leading to suboptimal style alignment.
We propose the Style-friendly SNR sampler, which aggressively shifts the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning to focus on noise levels where stylistic features emerge.
This enables models to better capture unique styles and generate images with higher style alignment. Our method allows diffusion models to learn and share new “style templates”, enhancing personalized content creation.
We demonstrate the ability to generate styles such as personal watercolor paintings, minimal flat cartoons, 3D renderings, multi-panel images, and memes with text, thereby broadening the scope of style-driven generation.
4.2. ChatGen: Automatic Text-to-Image Generation From FreeStyle Chatting
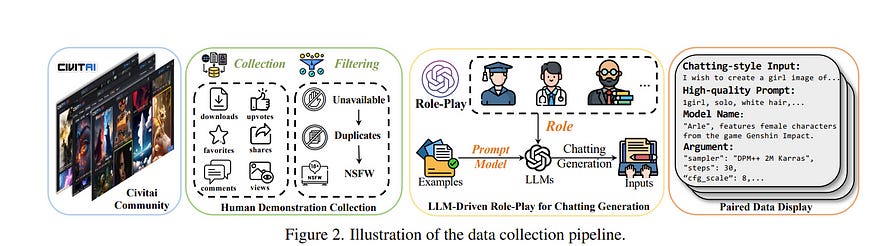
Despite the significant advancements in text-to-image (T2I) generative models, users often face a trial-and-error challenge in practical scenarios.
This challenge arises from the complexity and uncertainty of tedious steps such as crafting suitable prompts, selecting appropriate models, and configuring specific arguments, making users resort to labor-intensive attempts for desired images.
This paper proposes Automatic T2I generation, which aims to automate these tedious steps, allowing users to simply describe their needs in a freestyle chatting way.
To systematically study this problem, we first introduce ChatGenBench, a novel benchmark designed for Automatic T2I. It features high-quality paired data with diverse freestyle inputs, enabling comprehensive evaluation of automatic T2I models across all steps.
Additionally, recognizing Automatic T2I as a complex multi-step reasoning task, we propose ChatGen-Evo, a multi-stage evolution strategy that progressively equips models with essential automation skills.
Through extensive evaluation across step-wise accuracy and image quality, ChatGen-Evo significantly enhances performance over various baselines. Our evaluation also uncovers valuable insights for advancing automatic T2I.
4.3. Pathways on the Image Manifold: Image Editing via Video Generation

Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image.
Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing.
We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit.
This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image’s key aspects. Our approach achieves state-of-the-art results in text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation.
4.4. MARVEL-40M+: Multi-Level Visual Elaboration for High-Fidelity Text-to-3D Content Creation

Generating high-fidelity 3D content from text prompts remains a significant challenge in computer vision due to the limited size, diversity, and annotation depth of the existing datasets.
To address this, we introduce MARVEL-40M+, an extensive dataset with 40 million text annotations for over 8.9 million 3D assets aggregated from seven major 3D datasets.
Our contribution is a novel multi-stage annotation pipeline that integrates open-source pretrained multi-view VLMs and LLMs to automatically produce multi-level descriptions, ranging from detailed (150–200 words) to concise semantic tags (10–20 words).
This structure supports both fine-grained 3D reconstruction and rapid prototyping. Furthermore, we incorporate human metadata from source datasets into our annotation pipeline to add domain-specific information to our annotation and reduce VLM hallucinations.
Additionally, we develop MARVEL-FX3D, a two-stage text-to-3D pipeline. We fine-tune Stable Diffusion with our annotations and use a pretrained image-to-3D network to generate 3D textured meshes within 15s.
Extensive evaluations show that MARVEL-40M+ significantly outperforms existing datasets in annotation quality and linguistic diversity, achieving win rates of 72.41% by GPT-4 and 73.40% by human evaluators.
4.5. ROICtrl: Boosting Instance Control for Visual Generation

Natural language often struggles to accurately associate positional and attribute information with multiple instances, which limits current text-based visual generation models to simpler compositions featuring only a few dominant instances.
To address this limitation, this work enhances diffusion models by introducing regional instance control, where each instance is governed by a bounding box paired with a free-form caption. Previous methods in this area typically rely on implicit position encoding or explicit attention masks to separate regions of interest (ROIs), resulting in either inaccurate coordinate injection or large computational overhead.
Inspired by ROI-Align in object detection, we introduce a complementary operation called ROI-Unpool. Together, ROI-Align and ROI-Unpool enable explicit, efficient, and accurate ROI manipulation on high-resolution feature maps for visual generation.
Building on ROI-Unpool, we propose ROICtrl, an adapter for pretrained diffusion models that enables precise regional instance control. ROICtrl is compatible with community-finetuned diffusion models, as well as with existing spatial-based add-ons (\eg, ControlNet, T2I-Adapter) and embedding-based add-ons (\eg, IP-Adapter, ED-LoRA), extending their applications to multi-instance generation.
Experiments show that ROICtrl achieves superior performance in regional instance control while significantly reducing computational costs.
4.6. Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator

Subject-driven text-to-image generation aims to produce images of a new subject within a desired context by accurately capturing both the visual characteristics of the subject and the semantic content of a text prompt.
Traditional methods rely on time- and resource-intensive fine-tuning for subject alignment, while recent zero-shot approaches leverage on-the-fly image prompting, often sacrificing subject alignment.
In this paper, we introduce Diptych Prompting, a novel zero-shot approach that reinterprets as an inpainting task with precise subject alignment by leveraging the emergent property of diptych generation in large-scale text-to-image models.
Diptych Prompting arranges an incomplete diptych with the reference image in the left panel and performs text-conditioned inpainting on the right panel.
We further prevent unwanted content leakage by removing the background in the reference image and improving fine-grained details in the generated subject by enhancing attention weights between the panels during inpainting.
Experimental results confirm that our approach significantly outperforms zero-shot image prompting methods, resulting in images that are visually preferred by users.
Additionally, our method supports not only subject-driven generation but also stylized image generation and subject-driven image editing, demonstrating versatility across diverse image generation applications. Project page:
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
