


Important Computer Vision Papers for the Week from 19/08 to 25/08
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of August 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning

Diffusion models have emerged as frontrunners in text-to-image generation for their impressive capabilities. Nonetheless, their fixed image resolution during training often leads to challenges in high-resolution image generation, such as semantic inaccuracies and object replication.
This paper introduces MegaFusion, a novel approach that extends existing diffusion-based text-to-image generation models towards efficient higher-resolution generation without additional fine-tuning or extra adaptation. Specifically, we employ an innovative truncate and relay strategy to bridge the denoising processes across different resolutions, allowing for high-resolution image generation in a coarse-to-fine manner.
Moreover, by integrating dilated convolutions and noise re-scheduling, we further adapt the model’s priors for higher resolution. The versatility and efficacy of MegaFusion make it universally applicable to both latent-space and pixel-space diffusion models, along with other derivative models.
Extensive experiments confirm that MegaFusion significantly boosts the capability of existing models to produce images of megapixels and various aspect ratios, while only requiring about 40% of the original computational cost.
1.2. Iterative Object Count Optimization for Text-to-image Diffusion Models
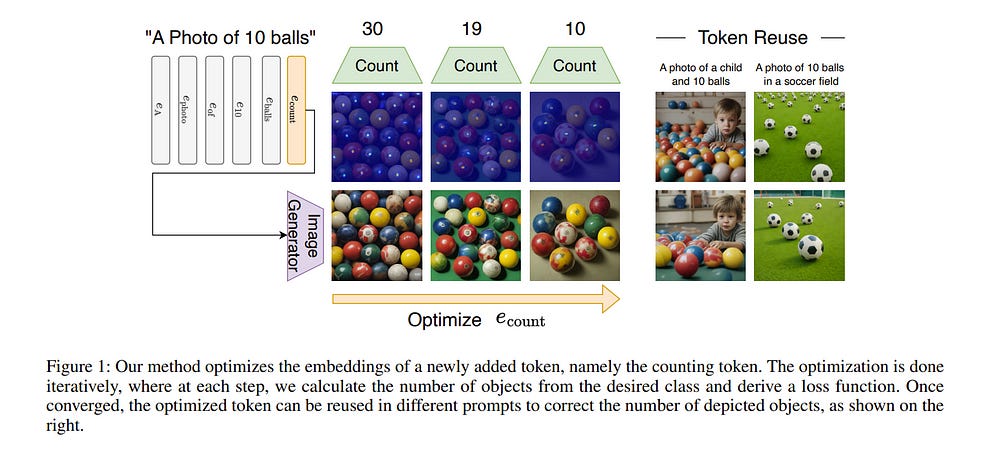
We address a persistent challenge in text-to-image models: accurately generating a specified number of objects. Current models, which learn from image-text pairs, inherently struggle with counting, as training data cannot depict every possible number of objects for any given object.
To solve this, we propose optimizing the generated image based on a counting loss derived from a counting model that aggregates an object\’s potential. Employing an out-of-the-box counting model is challenging for two reasons:
First, the model requires a scaling hyperparameter for the potential aggregation that varies depending on the viewpoint of the objects.
Second, classifier guidance techniques require modified models that operate on noisy intermediate diffusion steps.
To address these challenges, we propose an iterated online training mode that improves the accuracy of inferred images while altering the text conditioning embedding and dynamically adjusting hyperparameters.
Our method offers three key advantages: (i) it can consider non-derivable counting techniques based on detection models, (ii) it is a zero-shot plug-and-play solution facilitating rapid changes to the counting techniques and image generation methods, and (iii) the optimized counting token can be reused to generate accurate images without additional optimization. We evaluate the generation of various objects and show significant improvements in accuracy.
1.3. Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model

We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences.
We pre-train multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens.
By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches.
We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.
2. Vision Language Models (VLMs)
2.1. LongVILA: Scaling Long-Context Visual Language Models for Long Videos

Long-context capability is critical for multi-modal foundation models. We introduce LongVILA, a full-stack solution for long-context vision-language models, including system, model training, and dataset development.
On the system side, we introduce the first Multi-Modal Sequence Parallelism (MM-SP) system that enables long-context training and inference, enabling 2M context length training on 256 GPUs. MM-SP is also efficient, being 2.1x — 5.7x faster than Ring-Style Sequence Parallelism and 1.1x — 1.4x faster than Megatron-LM in text-only settings. Moreover, it seamlessly integrates with Hugging Face Transformers.
For model training, we propose a five-stage pipeline comprising alignment, pre-training, context extension, and long-short joint supervised fine-tuning. Regarding datasets, we meticulously construct large-scale visual language pre-training datasets and long video instruction-following datasets to support our multi-stage training process.
The full-stack solution extends the feasible frame number of VILA by a factor of 128 (from 8 to 1024 frames) and improves the long video captioning score from 2.00 to 3.26 (1.6x), achieving 99.5% accuracy in the 1400-frame video (274k context length) needle in a haystack.
LongVILA-8B also demonstrates a consistent improvement in performance on long videos within the VideoMME benchmark as the video frames increase.
2.2. Sapiens: Foundation for Human Vision Models

We present Sapiens, a family of models for four fundamental human-centric vision tasks — 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction.
Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images.
We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks.
The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability — model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion.
Sapiens consistently surpass existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
3. Video Understanding & Generation
3.1. Real-Time Video Generation with Pyramid Attention Broadcast

We present Pyramid Attention Broadcast (PAB), a real-time, high quality and training-free approach for DiT-based video generation. Our method is founded on the observation that attention difference in the diffusion process exhibits a U-shaped pattern, indicating significant redundancy.
We mitigate this by broadcasting attention outputs to subsequent steps in a pyramid style. It applies different broadcast strategies to each attention based on their variance for best efficiency. We further introduce broadcast sequence parallel for more efficient distributed inference.
PAB demonstrates superior results across three models compared to baselines, achieving real-time generation for up to 720p videos. We anticipate that our simple yet effective method will serve as a robust baseline and facilitate future research and application for video generation.
3.2. Factorized-Dreamer: Training A High-Quality Video Generator with Limited and Low-Quality Data

Text-to-video (T2V) generation has gained significant attention due to its wide applications to video generation, editing, enhancement and translation, \etc. However, high-quality (HQ) video synthesis is extremely challenging because of the diverse and complex motions that exist in the real world. Most existing works struggle to address this problem by collecting large-scale HQ videos, which are inaccessible to the community.
In this work, we show that publicly available limited and low-quality (LQ) data are sufficient to train an HQ video generator without recaptioning or finetuning. We factorize the whole T2V generation process into two steps: generating an image conditioned on a highly descriptive caption, and synthesizing the video conditioned on the generated image and a concise caption of motion details.
Specifically, we present Factorized-Dreamer, a factorized spatiotemporal framework with several critical designs for T2V generation, including an adapter to combine text and image embeddings, a pixel-aware cross-attention module to capture pixel-level image information, a T5 text encoder to better understand motion description, and a PredictNet to supervise optical flows.
We further present a noise schedule, which plays a key role in ensuring the quality and stability of video generation. Our model lowers the requirements in detailed captions and HQ videos and can be directly trained on limited LQ datasets with noisy and brief captions such as WebVid-10M, largely alleviating the cost of collecting large-scale HQ video-text pairs. Extensive experiments in a variety of T2V and image-to-video generation tasks demonstrate the effectiveness of our proposed Factorized-Dreamer.
3.3. TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models

In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging.
Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding.
Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2 or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos.
Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g).
We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings.
3.4. TrackGo: A Flexible and Efficient Method for Controllable Video Generation

Recent years have seen substantial progress in diffusion-based controllable video generation. However, achieving precise control in complex scenarios, including fine-grained object parts, sophisticated motion trajectories, and coherent background movement, remains a challenge.
In this paper, we introduce TrackGo, a novel approach that leverages free-form masks and arrows for conditional video generation. This method offers users with a flexible and precise mechanism for manipulating video content. We also propose the TrackAdapter for control implementation, an efficient and lightweight adapter designed to be seamlessly integrated into the temporal self-attention layers of a pretrained video generation model.
This design leverages our observation that the attention map of these layers can accurately activate regions corresponding to motion in videos. Our experimental results demonstrate that our new approach, enhanced by the TrackAdapter, achieves state-of-the-art performance on key metrics such as FVD, FID, and ObjMC scores.
3.5. xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations

We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI’s Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE).
VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments.
Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs.
The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
4. Image Editing & Generation
4.1. JPEG-LM: LLMs as Image Generators with Canonical Codec Representations

Recent work in image and video generation has been adopting the autoregressive LLM architecture due to its generality and potentially easy integration into multi-modal systems.
The crux of applying autoregressive training in language generation to visual generation is discretization — representing continuous data like images and videos as discrete tokens. Common methods of discretizing images and videos include modeling raw pixel values, which are prohibitively lengthy, or vector quantization, which requires convoluted pre-hoc training.
In this work, we propose to directly model images and videos as compressed files saved on computers via canonical codecs (e.g., JPEG, AVC/H.264). Using the default Llama architecture without any vision-specific modifications, we pretrain JPEG-LM from scratch to generate images (and AVC-LM to generate videos as a proof of concept), by directly outputting compressed file bytes in JPEG and AVC formats.
Evaluation of image generation shows that this simple and straightforward approach is more effective than pixel-based modeling and sophisticated vector quantization baselines (on which our method yields a 31% reduction in FID). Our analysis shows that JPEG-LM has an especial advantage over vector quantization models in generating long-tail visual elements.
Overall, we show that using canonical codec representations can help lower the barriers between language generation and visual generation, facilitating future research on multi-modal language/image/video LLMs.
4.2. TurboEdit: Instant text-based image editing

We address the challenges of precise image inversion and disentangled image editing in the context of few-step diffusion models. We introduce an encoder-based iterative inversion technique.
The inversion network is conditioned on the input image and the reconstructed image from the previous step, allowing for correction of the next reconstruction towards the input image. We demonstrate that disentangled controls can be easily achieved in the few-step diffusion model by conditioning on an (automatically generated) detailed text prompt.
To manipulate the inverted image, we freeze the noise maps and modify one attribute in the text prompt (either manually or via instruction-based editing driven by an LLM), resulting in the generation of a new image similar to the input image with only one attribute changed. It can further control the editing strength and accept instructive text prompts.
Our approach facilitates realistic text-guided image edits in real-time, requiring only 8 number of functional evaluations (NFEs) in inversion (one-time cost) and 4 NFEs per edit. Our method is not only fast, but also significantly outperforms state-of-the-art multi-step diffusion editing techniques.
4.3. Scalable Autoregressive Image Generation with Mamba

We introduce AiM, an autoregressive (AR) image-generative model based on Mamba architecture. AiM employs Mamba, a novel state-space model characterized by its exceptional performance for long-sequence modeling with linear time complexity, to supplant the commonly utilized Transformers in AR image generation models, aiming to achieve both superior generation quality and enhanced inference speed.
Unlike existing methods that adapt Mamba to handle two-dimensional signals via multi-directional scan, AiM directly utilizes the next-token prediction paradigm for autoregressive image generation. This approach circumvents the need for extensive modifications to enable Mamba to learn 2D spatial representations.
By implementing straightforward yet strategically targeted modifications for visual generative tasks, we preserve Mamba’s core structure, fully exploiting its efficient long-sequence modeling capabilities and scalability.
We provide AiM models in various scales, with parameter counts ranging from 148M to 1.3B. On the ImageNet1K 256*256 benchmark, our best AiM model achieves a FID of 2.21, surpassing all existing AR models of comparable parameter counts and demonstrating significant competitiveness against diffusion models, with 2 to 10 times faster inference speed.
5. Image Segmentation
5.1. Surgical SAM 2: Real-time Segment Anything in Surgical Video by Efficient Frame Pruning

Surgical video segmentation is a critical task in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, the Segment Anything Model 2 (SAM2) framework has shown superior advancements in image and video segmentation.
However, SAM2 struggles with efficiency due to the high computational demands of processing high-resolution images and complex and long-range temporal dynamics in surgical videos.
To address these challenges, we introduce Surgical SAM 2 (SurgSAM-2), an advanced model to utilize SAM2 with an Efficient Frame Pruning (EFP) mechanism, to facilitate real-time surgical video segmentation.
The EFP mechanism dynamically manages the memory bank by selectively retaining only the most informative frames, reducing memory usage and computational cost while maintaining high segmentation accuracy.
Our extensive experiments demonstrate that SurgSAM-2 significantly improves both efficiency and segmentation accuracy compared to the vanilla SAM2. Remarkably, SurgSAM-2 achieves a 3 times FPS compared with SAM2, while also delivering state-of-the-art performance after fine-tuning with lower-resolution data.
These advancements establish SurgSAM-2 as a leading model for surgical video analysis, making real-time surgical video segmentation in resource-constrained environments a feasible reality.
5.2. Segment Anything with Multiple Modalities
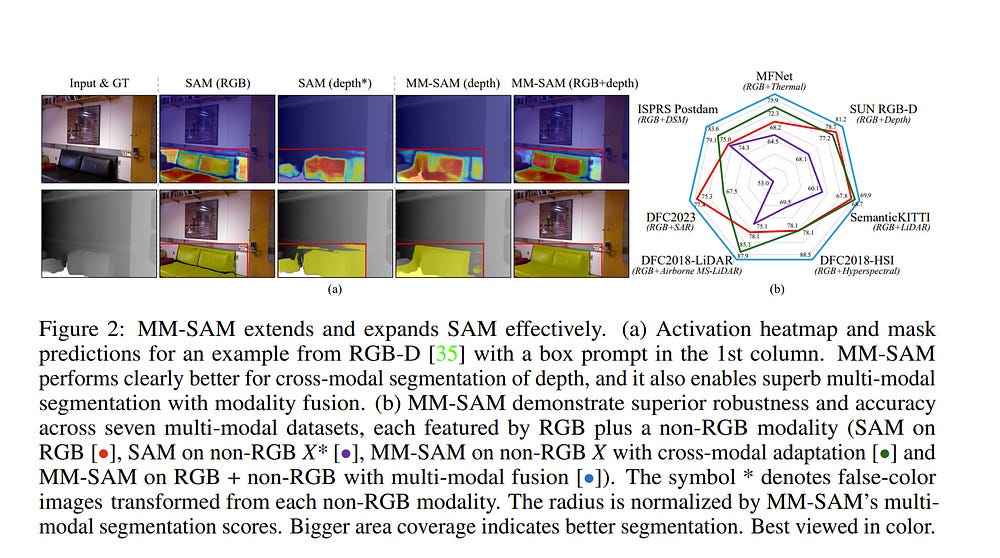
Robust and accurate segmentation of scenes has become one core functionality in various visual recognition and navigation tasks. This has inspired the recent development of the Segment Anything Model (SAM), a foundation model for general mask segmentation.
However, SAM is largely tailored for single-modal RGB images, limiting its applicability to multi-modal data captured with widely adopted sensor suites, such as LiDAR plus RGB, depth plus RGB, thermal plus RGB, etc. We develop MM-SAM, an extension and expansion of SAM that supports cross-modal and multi-modal processing for robust and enhanced segmentation with different sensor suites.
MM-SAM features two key designs, namely, unsupervised cross-modal transfer and weakly-supervised multi-modal fusion, enabling label-efficient and parameter-efficient adaptation toward various sensor modalities. It addresses three main challenges:
Adaptation toward diverse non-RGB sensors for single-modal processing
Synergistic processing of multi-modal data via sensor fusion
Mask-free training for different downstream tasks. Extensive experiments show that MM-SAM consistently outperforms SAM by large margins, demonstrating its effectiveness and robustness across various sensors and data modalities.
6. Object Tracking
6.1. MambaEVT: Event Stream-based Visual Object Tracking using State Space Model

Event camera-based visual tracking has drawn more and more attention in recent years due to the unique imaging principle and advantages of low energy consumption, high dynamic range, and dense temporal resolution. Current event-based tracking algorithms are gradually hitting their performance bottlenecks, due to the utilization of vision Transformer and the static template for target object localization.
In this paper, we propose a novel Mamba-based visual tracking framework that adopts the state space model with linear complexity as a backbone network. The search regions and target template are fed into the vision Mamba network for simultaneous feature extraction and interaction.
The output tokens of search regions will be fed into the tracking head for target localization. More importantly, we consider introducing a dynamic template update strategy into the tracking framework using the Memory Mamba network.
By considering the diversity of samples in the target template library and making appropriate adjustments to the template memory module, a more effective dynamic template can be integrated.
The effective combination of dynamic and static templates allows our Mamba-based tracking algorithm to achieve a good balance between accuracy and computational cost on multiple large-scale datasets, including EventVOT, VisEvent, and FE240hz.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
