


Important Computer Vision Papers for the Week from 02/12 to 08/12
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of December 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Video Generation & Editing
Text to Image Generation
Object Tracking
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. TinyFusion: Diffusion Transformers Learned Shallow
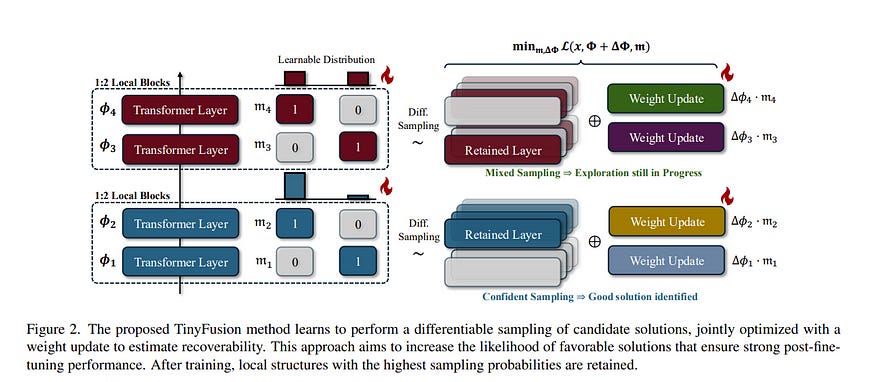
Diffusion Transformers have demonstrated remarkable capabilities in image generation but often come with excessive parameterization, resulting in considerable inference overhead in real-world applications.
In this work, we present TinyFusion, a depth-pruning method designed to remove redundant layers from diffusion transformers via end-to-end learning.
The core principle of our approach is to create a pruned model with high recoverability, allowing it to regain strong performance after fine-tuning. To accomplish this, we introduce a differentiable sampling technique to make pruning learnable, paired with a co-optimized parameter to simulate future fine-tuning.
While prior works focus on minimizing loss or error after pruning, our method explicitly models and optimizes the post-fine-tuning performance of pruned models. Experimental results indicate that this learnable paradigm offers substantial benefits for layer pruning of diffusion transformers, surpassing existing importance-based and error-based methods.
Additionally, TinyFusion exhibits strong generalization across diverse architectures, such as DiTs, MARs, and SiTs. Experiments with DiT-XL show that TinyFusion can craft a shallow diffusion transformer at less than 7% of the pre-training cost, achieving a 2 times speedup with an FID score of 2.86, outperforming competitors with comparable efficiency.
1.2. Distilling Diffusion Models to Efficient 3D LiDAR Scene Completion

Diffusion models have been applied to 3D LiDAR scene completion due to their strong training stability and high completion quality. However, the slow sampling speed limits the practical application of diffusion-based scene completion models since autonomous vehicles require an efficient perception of surrounding environments.
This paper proposes a novel distillation method tailored for 3D LiDAR scene completion models, dubbed ScoreLiDAR, which achieves efficient yet high-quality scene completion. ScoreLiDAR enables the distilled model to sample in significantly fewer steps after distillation.
To improve completion quality, we also introduce a novel Structural Loss, which encourages the distilled model to capture the geometric structure of the 3D LiDAR scene.
The loss contains a scene-wise term constraining the holistic structure and a point-wise term constraining the key landmark points and their relative configuration. Extensive experiments demonstrate that ScoreLiDAR significantly accelerates the completion time from 30.55 to 5.37 seconds per frame (> 5 times) on SemanticKITTI and achieves superior performance compared to state-of-the-art 3D LiDAR scene completion models.
1.3. SNOOPI: Supercharged One-step Diffusion Distillation with Proper Guidance

Recent approaches have yielded promising results in distilling multi-step text-to-image diffusion models into one-step ones. The state-of-the-art efficient distillation technique, i.e., SwiftBrushv2 (SBv2), even surpasses the teacher model’s performance with limited resources.
However, our study reveals its instability when handling different diffusion model backbones due to using a fixed guidance scale within the Variational Score Distillation (VSD) loss. Another weakness of the existing one-step diffusion models is the missing support for negative prompt guidance, which is crucial in practical image generation.
This paper presents SNOOPI, a novel framework designed to address these limitations by enhancing the guidance in one-step diffusion models during both training and inference. First, we effectively enhance training stability through Proper Guidance-SwiftBrush (PG-SB), which employs a random-scale classifier-free guidance approach.
By varying the guidance scale of both teacher models, we broaden their output distributions, resulting in a more robust VSD loss that enables SB to perform effectively across diverse backbones while maintaining competitive performance.
Second, we propose a training-free method called Negative-Away Steer Attention (NASA), which integrates negative prompts into one-step diffusion models via cross-attention to suppress undesired elements in generated images.
Our experimental results show that our proposed methods significantly improve baseline models across various metrics. Remarkably, we achieve an HPSv2 score of 31.08, setting a new state-of-the-art benchmark for one-step diffusion models.
1.4. NitroFusion: High-Fidelity Single-Step Diffusion through Dynamic Adversarial Training

We introduce NitroFusion, a fundamentally different approach to single-step diffusion that achieves high-quality generation through a dynamic adversarial framework. While one-step methods offer dramatic speed advantages, they typically suffer from quality degradation compared to their multi-step counterparts.
Just as a panel of art critics provides comprehensive feedback by specializing in different aspects like composition, color, and technique, our approach maintains a large pool of specialized discriminator heads that collectively guide the generation process.
Each discriminator group develops expertise in specific quality aspects at different noise levels, providing diverse feedback that enables high-fidelity one-step generation.
Our framework combines:
A dynamic discriminator pool with specialized discriminator groups to improve generation quality
Strategic refresh mechanisms to prevent discriminator overfitting
Global-local discriminator heads for multi-scale quality assessment, and unconditional/conditional training for balanced generation.
Additionally, our framework uniquely supports flexible deployment through bottom-up refinement, allowing users to dynamically choose between 1–4 denoising steps with the same model for direct quality-speed trade-offs.
Through comprehensive experiments, we demonstrate that NitroFusion significantly outperforms existing single-step methods across multiple evaluation metrics, particularly excelling in preserving fine details and global consistency.
2. Vision Language Models
2.1. PaliGemma 2: A Family of Versatile VLMs for Transfer

PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model.
We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning.
The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution.
We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
2.2. NVILA: Efficient Frontier Visual Language Models

Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention.
This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens.
This “scale-then-compress” approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment.
NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6–2.2X, and decoding latency by 1.2–2.8X. We will soon make our code and models available to facilitate reproducibility.
2.3. X-Prompt: Towards Universal In-Context Image Generation in Auto-Regressive Vision Language Foundation Models

In-context generation is a key component of large language models’ (LLMs) open-task generalization capability. By leveraging a few examples as context, LLMs can perform both in-domain and out-of-domain tasks. Recent advancements in auto-regressive vision-language models (VLMs) built upon LLMs have showcased impressive performance in text-to-image generation.
However, the potential of in-context learning for general image generation tasks remains largely unexplored. To address this, we introduce X-Prompt, a purely auto-regressive large-vision language model designed to deliver competitive performance across a wide range of both seen and unseen image generation tasks, all within a unified in-context learning framework.
X-Prompt incorporates a specialized design that efficiently compresses valuable features from in-context examples, supporting longer in-context token sequences and improving its ability to generalize to unseen tasks.
A unified training task for both text and image prediction enables X-Prompt to handle general image generation with enhanced task awareness from in-context examples. Extensive experiments validate the model’s performance across diverse seen image generation tasks and its capacity to generalize to previously unseen tasks.
2.4. VisionZip: Longer is Better but Not Necessary in Vision Language Models
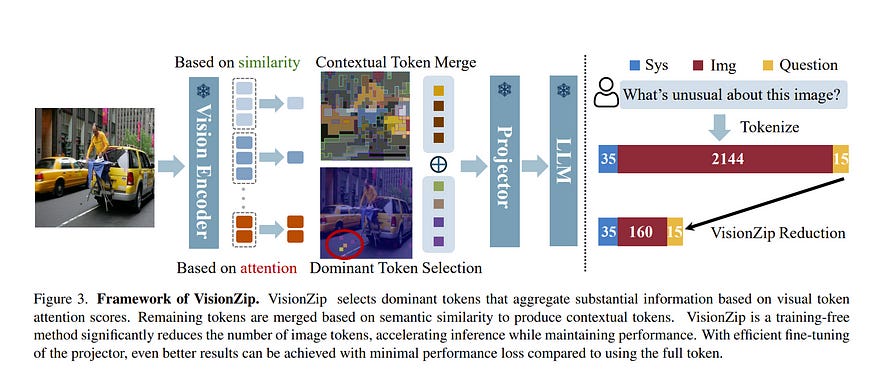
Recent advancements in vision-language models have enhanced performance by increasing the length of visual tokens, making them much longer than text tokens and significantly raising computational costs. However, we observe that the visual tokens generated by popular vision encoders, such as CLIP and SigLIP, contain significant redundancy.
To address this, we introduce VisionZip, a simple yet effective method that selects a set of informative tokens for input to the language model, reducing visual token redundancy and improving efficiency while maintaining model performance.
The proposed VisionZip can be widely applied to image and video understanding tasks and is well-suited for multi-turn dialogues in real-world scenarios, where previous methods tend to underperform. Experimental results show that VisionZip outperforms the previous state-of-the-art method by at least 5% performance gains across nearly all settings.
Moreover, our method significantly enhances model inference speed, improving the prefilling time by 8x and enabling the LLaVA-Next 13B model to infer faster than the LLaVA-Next 7B model while achieving better results. Furthermore, we analyze the causes of this redundancy and encourage the community to focus on extracting better visual features rather than merely increasing token length.
2.5. Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion

We present Florence-VL, a new family of multimodal large language models (MLLMs) with enriched visual representations produced by Florence-2, a generative vision foundation model.
Unlike the widely used CLIP-style vision transformer trained by contrastive learning, Florence-2 can capture different levels and aspects of visual features, which are more versatile to be adapted to diverse downstream tasks.
We propose a novel feature-fusion architecture and an innovative training recipe that effectively integrates Florence-2’s visual features into pretrained LLMs, such as Phi 3.5 and LLama 3.
In particular, we propose “depth-breath fusion (DBFusion)” to fuse the visual features extracted from different depths and under multiple prompts.
Our model training is composed of end-to-end pretraining of the whole model followed by finetuning of the projection layer and the LLM, on a carefully designed recipe of diverse open-source datasets that include high-quality image captions and instruction-tuning pairs.
Our quantitative analysis and visualization of Florence-VL’s visual features show its advantages over popular vision encoders on vision-language alignment, where the enriched depth and breath play important roles.
Florence-VL achieves significant improvements over existing state-of-the-art MLLMs across various multi-modal and vision-centric benchmarks covering general VQA, perception, hallucination, OCR, Chart, knowledge-intensive understanding, etc.
3. Video Generation & Editing
3.1. Video Depth without Video Models

Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth.
However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range.
An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs.
We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various frame rates back into a consistent video.
RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models.
3.2. Open-Sora Plan: Open-Source Large Video Generation Model

We introduce the Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs.
Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers.
Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data.
Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community.
3.3. VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation

Current video generation models excel at generating short clips but still struggle with creating multi-shot, movie-like videos. Existing models trained on large-scale data on the back of rich computational resources could be more adequate for maintaining a logical storyline and visual consistency across multiple shots of a cohesive script since they are often trained with a single-shot objective.
To this end, we propose VideoGen-of-Thought (VGoT), a collaborative and training-free architecture designed specifically for multi-shot video generation.
VGoT is designed with three goals in mind as follows. Multi-Shot Video Generation: We divide the video generation process into a structured, modular sequence, including
Script Generation, which translates a curt story into detailed prompts for each shot.
Keyframe Generation, responsible for creating visually consistent keyframes faithful to character portrayals.
Shot-Level Video Generation, which transforms information from scripts and keyframes into shots.
Smoothing Mechanism that ensures a consistent multi-shot output.
Reasonable Narrative Design: Inspired by cinematic scriptwriting, our prompt generation approach spans five key domains, ensuring logical consistency, character development, and narrative flow across the entire video.
Cross-Shot Consistency: We ensure temporal and identity consistency by leveraging identity-preserving (IP) embeddings across shots, which are automatically created from the narrative.
Additionally, we incorporate a cross-shot smoothing mechanism, which integrates a reset boundary that effectively combines latent features from adjacent shots, resulting in smooth transitions and maintaining visual coherence throughout the video.
Our experiments demonstrate that VGoT surpasses existing video generation methods in producing high-quality, coherent, multi-shot videos.
3.4. Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding

The rapid advancement of Multimodal Large Language Models (MLLMs) has significantly impacted various multimodal tasks. However, these models face challenges in tasks that require spatial understanding within 3D environments.
Efforts to enhance MLLMs, such as incorporating point cloud features, have been made, yet a considerable gap remains between the models’ learned representations and the inherent complexity of 3D scenes. This discrepancy largely stems from the training of MLLMs on predominantly 2D data, which restricts their effectiveness in comprehending 3D spaces.
To address this issue, in this paper, we propose a novel generalist model, i.e., Video-3D LLM, for 3D scene understanding. By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately.
Additionally, we have implemented a maximum coverage sampling technique to optimize the balance between computational costs and performance efficiency. Extensive experiments demonstrate that our model achieves state-of-the-art performance on several 3D scene understanding benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D.
4. Text to Image Generation
4.1. Switti: Designing Scale-Wise Transformers for Text-to-Image Synthesis

This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance.
We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart that facilitates 11% faster sampling and lower memory usage while also achieving slightly better generation quality.
Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. %may be not only unnecessary but potentially detrimental. By disabling guidance at these scales, we achieve an additional sampling acceleration of sim 20% and improve the generation of fine-grained details.
Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
5. Object Tracking
5.1. Efficient Track Anything

Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation.
The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track-anything models that produce high-quality results with low latency and model size.
Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation.
We take vanilla lightweight ViTs and efficient memory modules to build EfficientTAMs and train the models on SA-1B and SA-V datasets for video object segmentation and tracking tasks.
We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation and find that our proposed EfficientTAM with vanilla ViT performs comparably to the SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction.
On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as the iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
