


Important Computer Vision Papers for the Week from 22/07 to 28/07
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of July 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. DistilDIRE: A Small, Fast, Cheap, and Lightweight Diffusion Synthesized Deepfake Detection

A dramatic influx of diffusion-generated images has marked recent years, posing unique challenges to current detection technologies. While the task of identifying these images falls under binary classification, a seemingly straightforward category, the computational load is significant when employing the “reconstruction then compare” technique.
This approach, known as DIRE (Diffusion Reconstruction Error), not only identifies diffusion-generated images but also detects those produced by GANs, highlighting the technique’s broad applicability. To address the computational challenges and improve efficiency, we propose distilling the knowledge embedded in diffusion models to develop rapid deepfake detection models.
Our approach, aimed at creating a small, fast, cheap, and lightweight diffusion-synthesized deepfake detector, maintains robust performance while significantly reducing operational demands. Maintaining performance, our experimental results indicate an inference speed 3.2 times faster than the existing DIRE framework.
This advance not only enhances the practicality of deploying these systems in real-world settings but also paves the way for future research endeavors that seek to leverage diffusion model knowledge.
1.2. Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model

This paper addresses an important problem of object addition for images with only text guidance. It is challenging because the new object must be integrated seamlessly into the image with consistent visual context, such as lighting, texture, and spatial location.
While existing text-guided image inpainting methods can add objects, they either fail to preserve the background consistency or involve cumbersome human intervention in specifying bounding boxes or user-scribbled masks.
To tackle this challenge, we introduce Diffree, a Text-to-Image (T2I) model that facilitates text-guided object addition with only text control. To this end, we curate OABench, an exquisite synthetic dataset by removing objects with advanced image inpainting techniques.
OABench comprises 74K real-world tuples of an original image, an inpainted image with the object removed, an object mask, and object descriptions. Trained on OABench using the Stable Diffusion model with an additional mask prediction module, Diffree uniquely predicts the position of the new object and achieves object addition with guidance from only text.
Extensive experiments demonstrate that Diffree excels in adding new objects with a high success rate while maintaining background consistency, spatial appropriateness, and object relevance and quality.
1.3. BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation

By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details.
Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets.
To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details.
Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image.
For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details.
By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
2. Vision Language Models (VLMs)
2.1. EVLM: An Efficient Vision-Language Model for Visual Understanding

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens.
However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully.
This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible.
Our method primarily includes:
We are employing cross-attention to image-text interaction similar to Flamingo.
Utilize hierarchical ViT features.
Introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness.
Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
2.2. CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
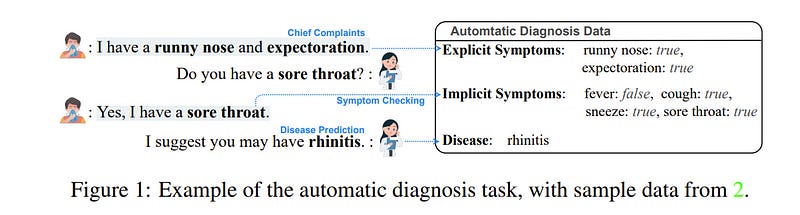
The field of medical diagnosis has undergone a significant transformation with the advent of large language models (LLMs), yet the challenges of interpretability within these models remain largely unaddressed. This study introduces Chain-of-Diagnosis (CoD) to enhance the interpretability of LLM-based medical diagnostics.
CoD transforms the diagnostic process into a diagnostic chain that mirrors a physician’s thought process, providing a transparent reasoning pathway. Additionally, CoD outputs the disease confidence distribution to ensure transparency in decision-making.
This interpretability makes model diagnostics controllable and aids in identifying critical symptoms for inquiry through the entropy reduction of confidences. With CoD, we developed DiagnosisGPT, capable of diagnosing 9604 diseases.
Experimental results demonstrate that DiagnosisGPT outperforms other LLMs on diagnostic benchmarks. Moreover, DiagnosisGPT provides interpretability while ensuring controllability in diagnostic rigor.
2.3. Efficient Inference of Vision Instruction-Following Models with Elastic Cache

In the field of instruction-following large vision-language models (LVLMs), the efficient deployment of these models faces challenges, notably due to the high memory demands of their key-value (KV) caches.
Conventional cache management strategies for LLMs focus on cache eviction, which often fails to address the specific needs of multimodal instruction-following models.
Recognizing this gap, in this paper, we introduce Elastic Cache, a novel approach that benefits from applying distinct acceleration methods for instruction encoding and output generation stages.
We investigate the metrics of importance in different stages and propose an importance-driven cache merging strategy to prune redundancy caches. Instead of discarding less important caches, our strategy identifies important key/value vectors as anchor points.
Surrounding less important caches are then merged with these anchors, enhancing the preservation of contextual information in the KV caches while yielding an arbitrary acceleration ratio. For instruction encoding, we utilize the frequency to evaluate the importance of caches.
Regarding output generation, we prioritize tokens based on their distance with an offset, by which both the initial and most recent tokens are retained. Results on a range of LVLMs demonstrate that Elastic Cache not only boosts efficiency but also notably outperforms existing pruning methods in language generation across various tasks.
2.4. VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models.
The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches.
Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder’s capacity by coupling it directly with the language prompt.
To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities.
Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
3. Video Understanding & Generation
3.1. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Large multimodal models (LMMs) are processing increasingly longer and richer inputs. Albeit the progress, few public benchmarks are available to measure such development.
To mitigate this gap, we introduce LongVideoBench, a question-answering benchmark that features video-language interleaved inputs up to an hour long. Our benchmark includes 3,763 varying-length web-collected videos with their subtitles across diverse themes, designed to comprehensively evaluate LMMs on long-term multimodal understanding.
To achieve this, we interpret the primary challenge as accurately retrieving and reasoning over detailed multimodal information from long inputs. As such, we formulate a novel video question-answering task termed referring reasoning.
Specifically, as part of the question, it contains a referring query that references related video contexts, called referred context. The model is then required to reason over relevant video details from the referred context. Following the paradigm of referring reasoning, we curate 6,678 human-annotated multiple-choice questions in 17 fine-grained categories, establishing one of the most comprehensive benchmarks for long-form video understanding.
Evaluations suggest that the LongVideoBench presents significant challenges even for the most advanced proprietary models (e.g. GPT-4o, Gemini-1.5-Pro, GPT-4-Turbo), while their open-source counterparts show an even larger performance gap.
In addition, our results indicate that model performance on the benchmark improves only when they are capable of processing more frames, positioning LongVideoBench as a valuable benchmark for evaluating future-generation long-context LMMs.
3.2. SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models

We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture the detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs.
This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as many spatial details as possible (e.g., with 24x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues.
As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for understanding details in the video. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks.
On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets.
3.3. MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequence

Recent advancements in video generation have primarily leveraged diffusion models for short-duration content. However, these approaches often fall short in modeling complex narratives and maintaining character consistency over extended periods, which is essential for long-form video production like movies.
We propose MovieDreamer, a novel hierarchical framework that integrates the strengths of autoregressive models with diffusion-based rendering to pioneer long-duration video generation with intricate plot progressions and high visual fidelity.
Our approach utilizes autoregressive models for global narrative coherence, predicting sequences of visual tokens that are subsequently transformed into high-quality video frames through diffusion rendering. This method is akin to traditional movie production processes, where complex stories are factorized into manageable scene capturing.
Further, we employ a multimodal script that enriches scene descriptions with detailed character information and visual style, enhancing continuity and character identity across scenes.
We present extensive experiments across various movie genres, demonstrating that our approach not only achieves superior visual and narrative quality but also effectively extends the duration of generated content significantly beyond current capabilities.
3.4. T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation

Text-to-video (T2V) generation models have advanced significantly, yet their ability to compose different objects, attributes, actions, and motions into a video remains unexplored.
Previous text-to-video benchmarks also neglect this important ability for evaluation. In this work, we conduct the first systematic study on compositional text-to-video generation.
We propose T2V-CompBench, the first benchmark tailored for compositional text-to-video generation. T2V-CompBench encompasses diverse aspects of compositionality, including consistent attribute binding, dynamic attribute binding, spatial relationships, motion binding, action binding, object interactions, and generative numeracy.
We further carefully design evaluation metrics of MLLM-based metrics, detection-based metrics, and tracking-based metrics, which can better reflect the compositional text-to-video generation quality of seven proposed categories with 700 text prompts.
The effectiveness of the proposed metrics is verified by correlation with human evaluations. We also benchmark various text-to-video generative models and conduct in-depth analysis across different models and different compositional categories.
We find that compositional text-to-video generation is highly challenging for current models, and we hope that our attempt will shed light on future research in this direction.
4. Image Editing & Generation
4.1. HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation

Human image animation involves generating videos from a character photo, allowing user control and unlocking the potential for video and movie production.
While recent approaches yield impressive results using high-quality training data, the inaccessibility of these datasets hampers fair and transparent benchmarking. Moreover, these approaches prioritize 2D human motion and overlook the significance of camera motions in videos, leading to limited control and unstable video generation.
To demystify the training data, we present HumanVid, the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. For the real-world data, we compile a vast collection of copyright-free real-world videos from the internet.
Through a carefully designed rule-based filtering strategy, we ensure the inclusion of high-quality videos, resulting in a collection of 20K human-centric videos in 1080P resolution. Human and camera motion annotation is accomplished using a 2D pose estimator and a SLAM-based method. For the synthetic data, we gather 2,300 copyright-free 3D avatar assets to augment existing available 3D assets.
Notably, we introduce a rule-based camera trajectory generation method, enabling the synthetic pipeline to incorporate diverse and precise camera motion annotation, which can rarely be found in real-world data. To verify the effectiveness of HumanVid, we establish a baseline model named CamAnimate, short for Camera-controllable Human Animation, that considers both human and camera motions as conditions.
Through extensive experimentation, we demonstrate that such simple baseline training on our HumanVid achieves state-of-the-art performance in controlling both human pose and camera motions, setting a new benchmark.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
