
How to Turn Any Website into a Graph Knowledge Base With A Production-Ready Co-Pilot
A Step-by-Step Guide to Building a Graph Knowledge Base and AI Co-Pilot from Any Website

This blog is written by Ali.Mz
Businesses hold vast amounts of information, but finding specific answers can often be frustrating and inefficient for customers or internal team members. A custom co-pilot with a holistic understanding of business, products, or services not only improves customer engagement but also streamlines internal knowledge access. This is where generating graph knowledge, along with a co-pilot UI for user interaction, becomes necessary.
In this tutorial, we’ll leverage the power of open-source tools to transform any existing website content into a ready-to-use AI co-pilot. You’ll learn how to:
Crawl and extract content from any website using Crawl4AI,
Convert that unstructured data into a graph knowledge base via the R2R (Reason-to-Retrieve) system, and
Deploy a GraphRAG UI locally that enables real-time, intelligent interaction with your knowledge base.

Table of Contents:
Meet the Tools
What is Crawl4ai?
What is R2R: Reason to Retrieve
Architecture Overview
Step-by-Step: Turning a Website Into a Graph-Based Co-Pilot
Step 1: Scrape website contents with Crawl4ai
Step 2: Build a Knowledge Graph with R2R and Start Querying
Conclusion
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. Meet the Tools
1.1. What is Crawl4ai?
Crawl4ai is an open-source web crawling and scraping framework built specifically for modern AI workflows. Unlike traditional scrapers, Crawl4ai is designed to extract and structure website content in a way that large language models (LLMs) can efficiently use.
Key highlights about this framework?
Built for Speed: It efficiently crawls and processes large websites, making it ideal for scaling up data extraction.
LLM-Ready Output: Converts noisy, unstructured HTML into clean, well-formatted Markdown — perfect for embedding or feeding into LLMs.
Light on Resources: Optimized to be memory-efficient, even when crawling hundreds of pages.
JavaScript Support: Works with modern, JavaScript-heavy websites that traditional scrapers often struggle with.
With these features, Crawl4ai acts as a bridge between any website’s content and any AI system that needs to understand it, which makes it a perfect choice for building a knowledge-rich co-pilot.
1.2. What is R2R: Reason to Retrieve
R2R (Reason to Retrieve) is an advanced, production-ready AI retrieval platform that offers Agentic Retrieval-Augmented Generation (RAG) with a RESTful API. It supports multimodal content ingestion (e.g. .txt, .pdf, .json, .png, .mp3, and more), hybrid search functionality, configurable GraphRAG, and user/document management.
Additionally, the platform features an intuitive UI for document ingestion, management, and co-pilot-style chat, making it a comprehensive end-to-end system for building intelligent knowledge interfaces.
Key Features That Make R2R Stand Out:
Multimodal Ingestion: Upload and parse data from diverse sources — PDFs, text files, JSON, images, even audio.
Hybrid Search: Combine vector search, full-text search, and Graph Retrieval-Augmented Generation (RAG).
GraphRAG: Automatically extract entities and relationships to generate a graph-based knowledge model, enabling multi-hop reasoning and deeper insights.
Deep Research Agent: R2R’s built-in agent uses multi-step reasoning to pull from your internal knowledge base (and optionally the web) to answer complex questions with context.
Collections & User Management: Organize documents into collections and manage user access out of the box.
2. Architecture Overview
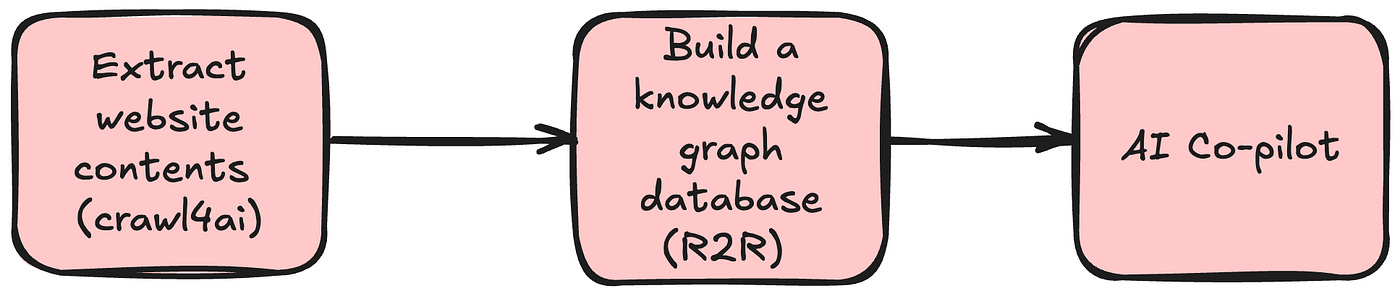
3. Step-by-Step: Turning a Website Into a Graph-Based Co-Pilot
In this example, we’ll walk through how to transform a static website into a dynamic, graph-powered co-pilot.
We’ll begin by using Crawl4ai to extract structured product details from Books to Scrape, a website intentionally designed for web scraping practice. Once we have the structured content (such as book titles, prices, categories, and availability), we’ll feed it into a pipeline that automatically builds a knowledge graph.
This graph will identify key entities (like books, descriptions, prices, etc.) and the relationships between them to provide the AI co-pilot with context to reason against user questions.
Step 1: Scrape website contents with Crawl4ai
To kick things off, we’ll use one of Crawl4ai’s powerful and flexible deep crawling features to go beyond a single page and collect structured content from across an entire site, while staying within defined domain boundaries.
Crawl4ai provides you with fine-grained control over how the crawler behaves, including how deep it navigates, which URLs it follows, and how it processes content.
Before we begin scraping, let’s set up our development environment.
We will use UV, my favourite Python package manager, to create the virtual environment with a specific name and Python version:
uv venv .venv --python=python3.12
source .venv/bin/activate2. Run the following command to install dependencies for crawling website contents:
pip install crawl4ai pydanticThis installs Crawl4ai for scraping and Pydantic for handling structured data validation.
3. Crawl4ai supports multiple LLM providers for extracting structured data from unstructured web content. You can use OpenAI, Groq, or even Ollama (for local models). That said, for extracting a large volume of detailed content accurately, I recommend using stronger hosted models like those from OpenAI or Groq.
echo -e “OPENAI_API_KEY=$(read -sp ‘Enter OpenAI API key: ‘ okey && echo $okey)\nGROQ_API_KEY=$(read -sp ‘Enter Groq API key: ‘ gkey && echo $gkey)” > .env && echo -e “\n✅ .env file created successfully”This will prompt you to enter your API keys and automatically generate a .env file, keeping your credentials secure and separate from your codebase.
4. Next, it’s time to extract structured product data from Books to Scrape — specifically, details like title, price, availability, and category. To efficiently cover all product pages, we’ll use a Breadth-First Search (BFS) crawling strategy. This approach systematically traverses the site’s hierarchy, which lets us capture relevant product details page by page. Below is the complete Python script that handles the crawling and structures the extracted content in a clean format:
import getpass
import os
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, BrowserConfig, CacheMode, LLMConfig
from crawl4ai.content_scraping_strategy import LXMLWebScrapingStrategy
from crawl4ai.deep_crawling import BFSDeepCrawlStrategy
from crawl4ai.deep_crawling.filters import (
FilterChain,
URLPatternFilter,
ContentTypeFilter
)
from pydantic import BaseModel
from crawl4ai.extraction_strategy import LLMExtractionStrategy
import json
from dotenv import load_dotenv
load_dotenv()
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f”{var}: “)
_set_env(”OPENAI_API_KEY”)
_set_env(”GROQ_API_KEY”)
class ProductDetails(BaseModel):
upc: str
type: str
price: str
inventory_count: int
class Product(BaseModel):
title: str
description: str
details: ProductDetails
extraction_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider=”groq/deepseek-r1-distill-llama-70b”, api_token=os.getenv(’GROQ_API_KEY’)),
# llm_config = LLMConfig(provider=”openai/gpt-4o-mini”, api_token=os.getenv(’OPENAI_API_KEY’)),
schema=Product.model_json_schema(),
extraction_type=”schema”,
instruction=”Extract all product objects specified in the schema from the text.”,
chunk_token_threshold=1200,
overlap_rate=0.1,
apply_chunking=True,
input_format=”html”,
extra_args={”temperature”: 0.1, “max_tokens”: 1000},
verbose=True
)
async def run_advanced_crawler():
# Create a sophisticated filter chain
filter_chain = FilterChain([
# URL patterns to include
URLPatternFilter(patterns=[”*catalogue*”], reverse=False),
# URL patterns to exclude
URLPatternFilter(patterns=[”*category*”, “*/books/*”], reverse=True),
# Content type filtering
ContentTypeFilter(allowed_types=[”text/html”])
])
# Set up the configuration
config = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=2,
include_external=False,
max_pages=2,
filter_chain=filter_chain,
),
cache_mode=CacheMode.BYPASS,
extraction_strategy=extraction_strategy,
scraping_strategy=LXMLWebScrapingStrategy(),
verbose=True
)
# Execute the crawl
outputs = []
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
results = await crawler.arun(”https://books.toscrape.com/index.html”, config=config)
for result in results:
if result.success:
url = result.url
try:
data = json.loads(result.extracted_content)
# Check if the result contains an error object
if isinstance(data, list) and len(data) > 0:
if any(item.get(’error’, False) for item in data if isinstance(item, dict)):
# Find the error item
error_items = [item for item in data if isinstance(item, dict) and item.get(’error’, False)]
error_content = error_items[0].get(’content’, ‘Unknown error’) if error_items else ‘Unknown error’
print(f”Error in extracted data from {url}: {error_content}”)
continue # Skip to the next URL
print(f”Successfully extracted data from {url}”)
# Show usage stats
extraction_strategy.show_usage() # prints token usage stats
# Add the URL to each item in the list for reference
for item in data:
if isinstance(item, dict):
item[’source_url’] = url
# Add each successful item to the results
outputs.extend(data)
except json.JSONDecodeError:
print(f”Error decoding JSON from {url}: {result.extracted_content}”)
else:
print(f”Error crawling {url}: {result.error_message}”)
# Save all results to a JSON file
if outputs:
output_file = “extracted_products.json”
with open(output_file, ‘w’, encoding=’utf-8’) as f:
json.dump(outputs, f, indent=4, ensure_ascii=False)
print(f”Data for {len(outputs)} products saved to {output_file}”)
if __name__ == “__main__”:
asyncio.run(run_advanced_crawler())Explaining the code
Let’s walk through the script step by step to understand how each part contributes to building the scraper pipeline.
Setting API Keys for LLM Providers
This is where we make sure our LLM providers’ API keys are correctly loaded into the environment. Depending on which model provider you prefer, you can include one of the following lines.
✅ If you’re using Ollama with local models, you can safely skip this step.
_set_env(”OPENAI_API_KEY”)
_set_env(”GROQ_API_KEY”)Defining the Data Model with Pydantic
To ensure our extracted data is clean, consistent, and machine-readable, we use Pydantic to define a structured schema for product properties. Below, we define a nested structure that ProductDetails is embedded inside the main Product model. This schema not only validates the output but also acts as a blueprint for the LLM, guiding it to generate well-structured results.
💡 You can expand the schema based on what’s available (or missing) in the data.
class ProductDetails(BaseModel):
upc: str
type: str
price: str
inventory_count: int
class Product(BaseModel):
title: str
description: str
details: ProductDetailsExtracting contents with LLM strategy
When dealing with complex or unstructured data that can’t be easily parsed with CSS or XPath selectors, LLM-based extraction could be a good choice. In this step, we use the LLMExtractionStrategy class from Crawl4ai to extract structured product data directly from raw HTML. You can find more information about this strategy in this online document.
Key Components of the Strategy:
LLM_Config: We’re using Groq’s DeepSeek R1, a fast and cost-effective LLaMA 70B model that’s well-suited for structured tasks like data extraction. Crawl4ai supports any model integrated via Lightllm, using a provider string like“groq/deepseek-chat”,“openai/gpt-4o”, or“ollama/llama”to specify the LLM.schema: Here, we define the expected structure of the output, which acts as a contract between your application and the LLM. We use theProductthe Pydantic model we defined earlier. This constraint helps reduce hallucinations and ensures the output is easily validated.instruction: A guiding prompt that tells the LLM what kind of data to extract and how to format it.chunk_token_threshold&overlap_rate: To stay within token limits, Crawl4ai automatically splits large HTML or markdown into smaller overlapping segments.
⚠️ Note: LLM-based extraction is powerful but can be slower and more expensive because of higher token usage. If your data is consistently structured, Crawl4ai also supports static, non-LLM extraction strategies for faster and cheaper results.
extraction_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider=”groq/deepseek-r1-distill-llama-70b”, api_token=os.getenv(’GROQ_API_KEY’)),
# llm_config = LLMConfig(provider=”openai/gpt-4o-mini”, api_token=os.getenv(’OPENAI_API_KEY’)),
schema=Product.model_json_schema(),
extraction_type=”schema”,
instruction=”Extract all product objects specified in the schema
from the text.”,
chunk_token_threshold=1200,
overlap_rate=0.1,
apply_chunking=True,
input_format=”html”,
extra_args={”temperature”: 0.1, “max_tokens”: 1000},
verbose=True
)Setting Up a Filter Chain for Targeted Crawling
One of the powerful features of Crawl4ai is its ability to chain filters to include or exclude specific patterns in a given URL. This is especially useful when you’re targeting very specific content on a site, like product detail pages. In our case, we want to extract only the individual book listings from Books to Scrape, without wasting resources on irrelevant pages like category listings or the homepage.
# Create a sophisticated filter chain
filter_chain = FilterChain([
# URL patterns to include
URLPatternFilter(patterns=[”*catalogue*”], reverse=False),
# URL patterns to exclude
URLPatternFilter(patterns=[”*category*”, “*/books/*”], reverse=True),
# Content type filtering
ContentTypeFilter(allowed_types=[”text/html”])
])Configuring Crawler
CrawlerRunConfig class allows us to define the core behavior of the crawler, such as how it handles URL filtering, content extraction, dynamic elements, and caching. It’s essentially a blueprint for each crawl operation.
In this step, we’ll combine the deep crawl strategy (BFS) and the LLM-based extraction strategy from earlier to create a comprehensive configuration for our crawler.
# Set up the configuration
config = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=2,
include_external=False,
max_pages=2,
filter_chain=filter_chain,
),
cache_mode=CacheMode.BYPASS,
extraction_strategy=extraction_strategy,
scraping_strategy=LXMLWebScrapingStrategy(),
verbose=True
)Executing the Crawl: Bringing It All Together
The AsyncWebCrawler class is the core component for performing asynchronous web crawling in Crawl4ai. It enables scraping pages concurrently, which significantly speeds up the extraction process. We use the BrowserConfig to fine-tune global crawler behaviour, like running in headless mode or setting a custom user agent.
In this step, we execute the crawl by running the arun() method with the main URL and the custom configuration we defined earlier. This operation runs inside an async context manager, which allows for efficient asynchronous execution.
# Execute the crawl
outputs = []
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
results = await crawler.arun(”https://books.toscrape.com/index.html”, config=config)Finally, once the content extraction from all crawled pages is complete, we iterate over all extracted content and turn it into a structured JSON format, ready for use in generating a knowledge graph.
Here’s an example of what the output might look like for one book. Notice how the fields map directly to the Pydantic models we defined earlier:
[
{
“title”: “A Light in the Attic”,
“description”: “It’s hard to imagine a world without A Light in the Attic. This now-classic collection of poetry and drawings from Shel Silverstein celebrates its 20th anniversary with this special edition. Silverstein’s humorous and creative verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids sit still and read these rhythmic words and laugh and smile and love th It’s hard to imagine a world without A Light in the Attic. This now-classic collection of poetry and drawings from Shel Silverstein celebrates its 20th anniversary with this special edition. Silverstein’s humorous and creative verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids sit still and read these rhythmic words and laugh and smile and love that Silverstein. Need proof of his genius? RockabyeRockabye baby, in the treetopDon’t you know a treetopIs no safe place to rock?And who put you up there,And your cradle, too?Baby, I think someone down here’sGot it in for you. Shel, you never sounded so good. ...more”,
“details”: {
“upc”: “a897fe39b1053632”,
“type”: “Books”,
“price”: “£51.77”,
“inventory_count”: 22
},
“error”: false,
“source_url”: “https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html”
}
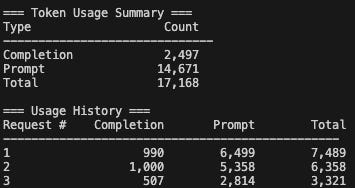
]One helpful feature of Crawl4ai is that it provides clear insights into how many tokens were consumed during the LLM-based extraction process. This can be especially useful for keeping track of API costs or optimizing the extraction strategy.
extraction_strategy.show_usage() # prints token usage statsAgain, the LLM-based extraction strategy could be very token-intensive depending on the number of pages retrieved and the amount of content in those pages. So, be careful when using this strategy and always start with a limited number of pages for experimentation.
Here’s a sample output of my token usage after extracting just two pages:
Step 2: Build a Knowledge Graph with R2R and Start Querying
So far, we’ve successfully built a pipeline that extracts structured content from our target website. The final step is to transform that content into a knowledge graph. For that, we’ll use R2R (Reason to Retrieve) to automatically build knowledge graphs and provide an interactive Co-Pilot UI for querying the data.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.