
How I Built a Tool-Calling Llama Agent with a Custom MCP Server
Building Tool Calling Llama Agent with a Custom MCP Server: Step by Step Guide


1. Introduction
In this article, I’ll walk through the development of a local AI agent that communicates with a previously built MCP(Model Context Protocol) server to generate context-aware responses using tool-calling.
Why I started this project
This article is a follow-up to my previous article, where I introduced a custom MCP server that connects to my personal Obsidian knowledge base. Rather than using the official MCP server with file system access, I chose to build my own for several reasons:
To enforce read-only access to my file system
To avoid exposing the directory structure of file paths to the external AI model
To deeply understand how the MCP works by implementing it
For more details, please refer to my previous article.
After building the MCP server, I wanted to address a new challenge: dependency on external AI models. While Claude has demonstrated excellent reasoning capabilities, its usage is limited unless you’re on a paid plan. More importantly, relying on external AI services means that the contents of my private knowledge notes are still being sent outside my local environment.
This article covers the next steps in building a fully local, private agent:
Implementing an MCP client that connects to the MCP server
Integrating a local LLM model for response generation
Building an LLM agent that uses both MCP and the model to answer questions
For this purpose, I chose not to use frameworks like LangChain, so the entire flow is transparent and easy to understand.
2. Integration of sLLM with Tool-Calling Support
2.1. Small Language Model for Local Use
In agent development, the most critical thing is the brain — the LLM. The quality of the generated responses depends heavily on the model’s reasoning ability. However, since the goal is to run everything locally, using a massive LLM is not feasible. Instead, we must rely on small Language Model(sLLM) that can run on a local GPU or CPU environment.
But not all sLLMs are suitable. If the model’s response quality is too low or it lacks the ability to follow tool-calling instructions, it becomes unusable for this kind of agent architecture.
Previously, I experimented with the Llama 3.1 8B-Instruct model, which delivered impressive results. I used it in a project where multiple models, each with different system prompts(personas), engaged in discussions on selected topics to generate synthetic(artificial) text data. If you’re interested in the details, please check out this article.
While the Llama 3.1 8B-Instruct model also supports tool-calling, for this project, I opted for Llama 3.2 version model. The 1B and 3B models from Llama 3.2 are lightweight models designed for on-device agentic applications, which keep all data local and help preserve user privacy.
According to Meta’s benchmarking results, the Llama 3.2 models strike a good balance between size and performance. Despite their smaller size, they offer reasonable response quality and support for tool-calling, making them well-suited for this project.
As explained in Meta’s official blog post, the Llama 3.2 models were created by applying structured pruning to the Llama 3.1 8B model in a single-shot manner. To recover performance after pruning, Meta used knowledge distillation from multiple Llama 3.1 models, as illustrated in the diagram below.

I won’t go into the technical details here. If you’re curious, I encourage you to read through Meta’s official blog post.
2.1. The Tool Calling Process of LLM
How does the LLM invoke a tool and generate a response? The overall tool-calling process is illustrated below.
When information about available tools is provided — either through the system prompt or user prompt — the LLM determines whether a tool should be invoked. If so, it generates a function call definition as its response.
The LLM application then parses the function call, executes the corresponding tool, and feeds the result back to the model. Based on the tool’s output, the model can generate a synthesized response.

In this project, the Tools component in the diagram is replaced by the MCP Client, which is responsible for invoking tools. The following explanation is based on the official Llama 3.1 documentation. If you’re already familiar with this, you can skip ahead to the next chapter.
Let’s briefly review the special tokens and role structure that form the backbone of prompt formatting.
Special Tokens
<|begin_of_text|>: Specifies the start of the prompt.
<|start_header_id|> {role} <|end_header_id|> : Enclose the role for a particular message.
<|eot_id|> : (End of turn); signals to the executor that the model has finished generating a response.
Supported Roles
system: Defines the context in which the model operates. It usually includes instructions, rules, guidelines, or background information to help the model’s behavior
user It represents the input from a human user. It includes the inputs, commands, and questions to the model
assistant: Represents the response generated by the AI model based on the context
ipython: Semantically, this role means “tool”. This is used to return the output of a tool invocation back to the model from the executor.
Let’s take a look at how the LLM determines when to invoke and how it generates a response.
1) System Prompt with Tool Definition
The system prompt includes tool definitions in JSON format, specifying the available tools and their parameters. This definition can also be included in the user prompt, although placing it in the system prompt is generally preferred for clarity.
<|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out. If the given question lacks the parameters required by the function,also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "get_user_name",
"description": "Retrieve a name for a specific user by their unique identifier. Note that the provided function is in Python 3 syntax.",
"parameters": {
"type": "dict",
"required": [
"user_id"
],
"properties": {
"user_id": {
"type": "integer",
"description": "The unique identifier of the user. It is used to fetch the specific user details from the database."
}
}
}
}
]
<|eot_id|>
2) User Prompt to LLM
The system prompt, which includes the tool definitions, is combined with the user prompt that contains the actual query. To make the LLM to generate a response by completing the sentence, the message is concluded with an assistant header.
<|start_header_id|>user<|end_header_id|>
Can you retrieve the name of the user with the ID 7890?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>3) Response with tool-call
In this step, the LLM determines that answering the user’s query requires a function call. It responds by generating a function call expression that matches the format specified in the system prompt.
[get_user_name(user_id=7890)]
<|eot_id|>4) Original Prompt + Tool Response
The application executes the requested function and appends the result back to the prompt. The role ipython is used to mark the tool result when passing it back to the model.
...
<|start_header_id|>user<|end_header_id|>
Can you retrieve the name of the user with the ID 7890?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
[get_user_name(user_id=7890)]
<|eot_id|>
<|start_header_id|>ipython<|end_header_id|>
{"output": "Hyunjong Lee"}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>5) Synthesized Response
Finally, the model produces a complete response using the tool output:
The name of user who has the ID is “Hyunjong Lee”.
<eot_id>Even lightweight models like Llama 3.2 1B and 3B are capable of performing tool-calling. However, according to Meta’s official documentation, for building stable tool-aware conversational applications, it is recommended to use either the 70 B-Instruct or 405 B-Instruct models.
While the 8 B-Instruct model supports zero-shot tool calling, Meta’s blog notes that it cannot reliably maintain a conversation when tool definitions are included in the prompt. Therefore, when working with smaller models, it’s often necessary to remove tool instructions from the prompt to ensure smoother interaction between the user and the AI model.
This is a critical consideration for generating high-quality responses and one you should definitely keep in mind.
Note: We recommend using Llama 70B-instruct or Llama 405B-instruct for applications that combine conversation and tool calling. Llama 8B-Instruct can not reliably maintain a conversation alongside tool calling definitions. It can be used for zero-shot tool calling, but tool instructions should be removed for regular conversations between the model and the user. — from meta AI notes
3. Building LLM Agent
Now, let’s take a look at the architecture of the agent I built. It closely follows the tool-calling process described above, with a few additional components to enable communication with the MCP server.
The core components are: MCP Client & Manager, LLM, and Agent
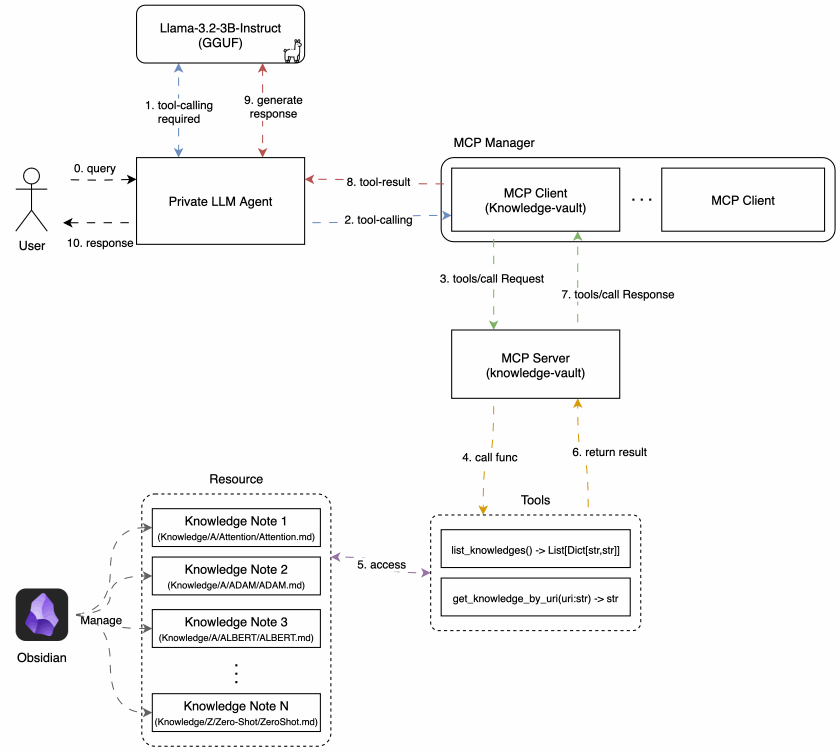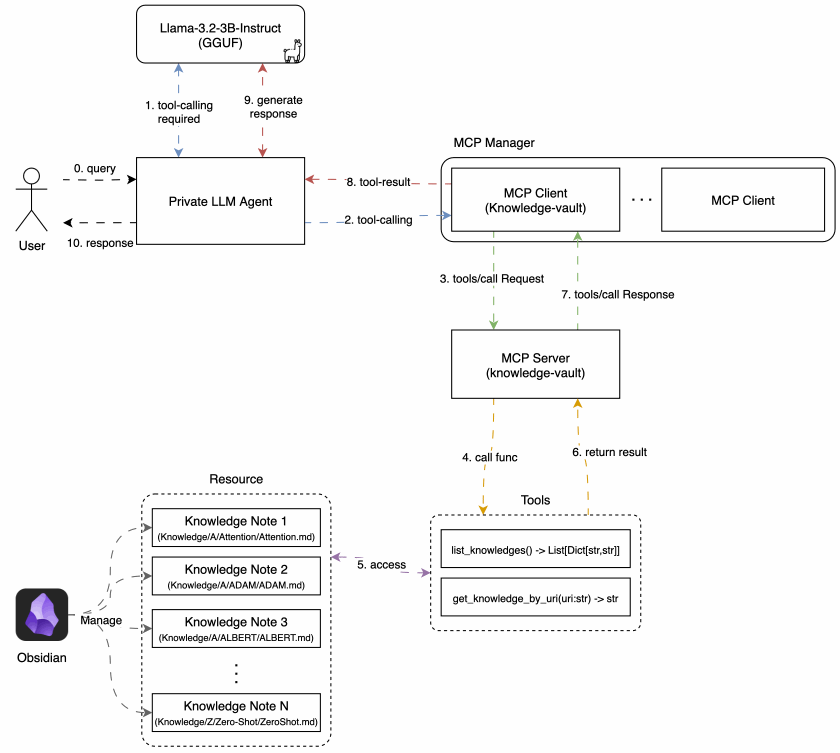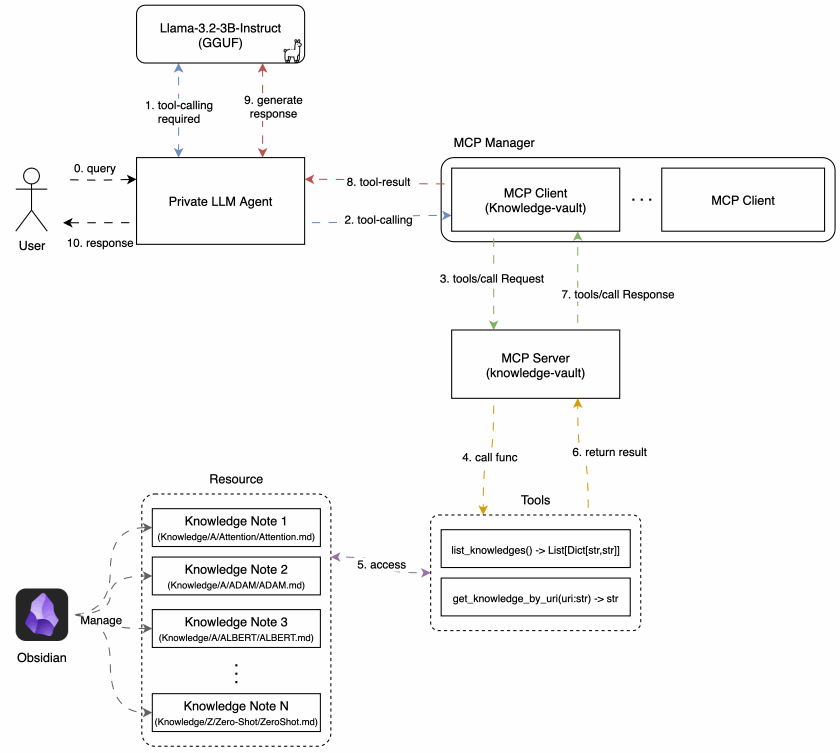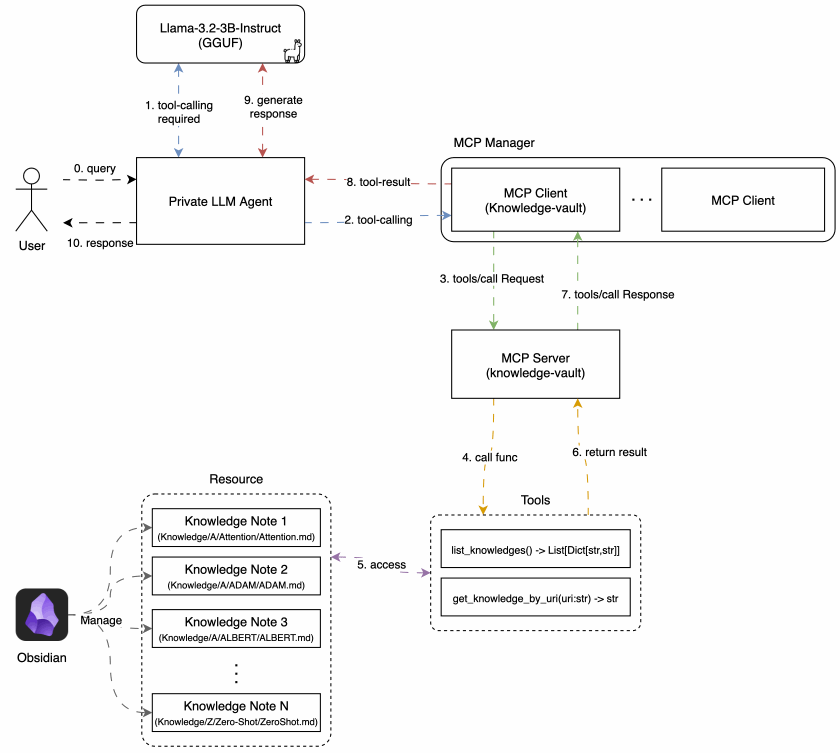
As this article contains a significant amount of code, only essential parts are shown here for clarity. You can find the full source code in this GitHub repository.
3.1. MCP Client and Manager
A. MCP Client
First, we need an MCP Client capable of establishing a 1:1 connection with the MCP server. This was implemented using the Python MCP SDK, following the official MCP documentation.
Below is the MCPClient class, which handles the connection to the server. Since the custom MCP server I built communicates over standard input/output(stdio), the client spawns the server process, connects to it via its read/write streams.
class MCPClient:
def __init__(self):
self.session = None
self.name = ''
self.exit_stack = AsyncExitStack()
async def connect_to_server(self, server_script_path:str):
server_params = StdioServerParameters(
command = "python",
args=[server_script_path],
env=None
)
# spawaning a process for running a mcp server
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.read, self.write = stdio_transport
# init session using read/write pipes of the process spawned
self.session = await self.exit_stack.enter_async_context(ClientSession(self.read, self.write))
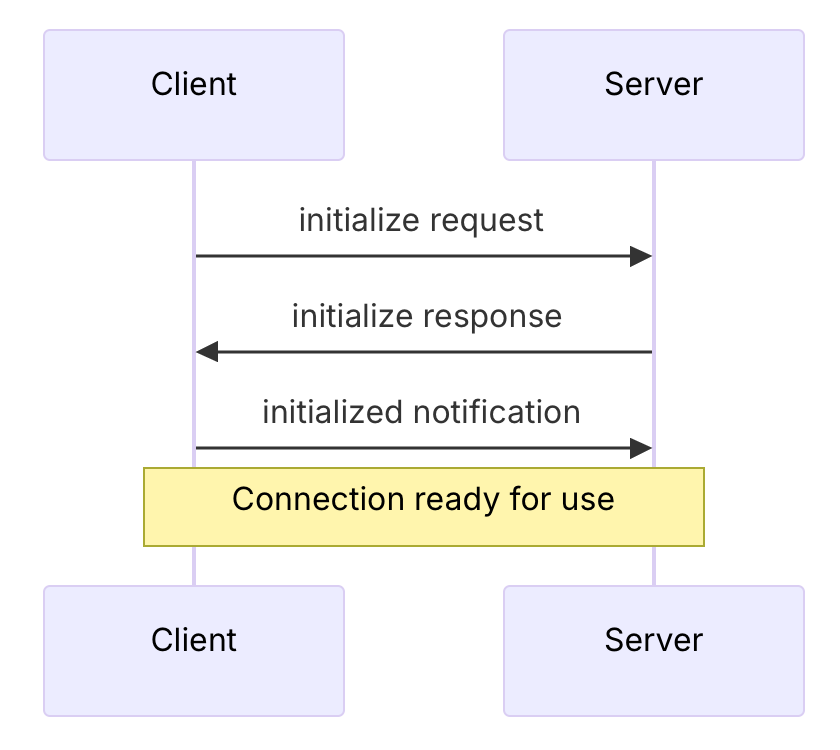
...After creating the client session, the client follows the MCP connection lifecycle. It first sends an initialization request to the MCP server, waits for a response, and then completes the handshake by sending an initialized notification as an acknowledgement.

 | A guest post by
|