
Hands-on Introduction to DuckDB

DuckDB has been gaining significant attention in the data community, with many calling it a game-changer for analytical workloads. Originally developed in 2019 by researchers at CWI in the Netherlands, DuckDB was designed to bring high-performance SQL analytics directly into applications without the need for complex database infrastructure.
In this article, we’ll explore the fundamentals of DuckDB, why it’s gaining popularity among data professionals, and how to get started with it using Python. We’ll cover installation, basic SQL operations, persistent storage, and how to query data from various sources like CSV, JSON, and Parquet files. Finally, we’ll walk through a complete example to showcase DuckDB’s capabilities in answering key business questions.
All data used in this article is available at: Anwar11234/duckdb-article-data

Table of Contents:
What is DuckDB?
Why DuckDB?
Installing DuckDB
A complete example
1. What is DuckDB?
According to duckdb.org, DuckDB is an in-process SQL OLAP database management system. Let’s break down this definition to understand what it means:
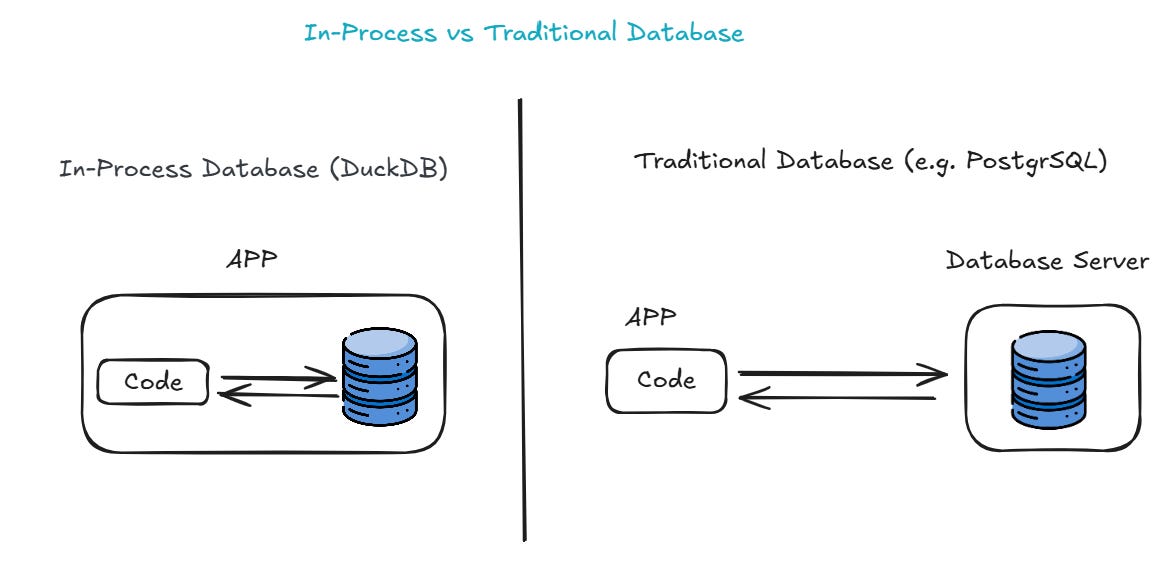
1.1. In-process
This means that it’s directly embedded within our application, not a separate database management system that you have to manage in another service such as PostgreSQL or MySQL. Unlike these DBMSs, DuckDB operates in the program you’re working on, and you can do all the things you do with a DBMS such as creating, querying, and modifying tables within your program. This makes DuckDB much easier to work with. The below figure illustrates what an in-process database means:
2. SQL
This just means it’s a relational database management system, which uses SQL to manage and query the data.
3. OLAP
OLAP is short for Online Analytical Processing, which is a way of processing data that focuses on efficiently reading, analyzing, and summarizing large datasets to support decision-making. Unlike OLTP (Online Transactional Processing), which is optimized for efficiently inserting, updating, and retrieving small amounts of data in real-time. In short, this means that DuckDB is optimized for data analytics. Read this if you want to learn more about OLAP
To summarize, DuckDB is a relational database management system that’s optimized for data analytics and is embedded within our application.
2. Why DuckDB?

2.1. Simplicity
As mentioned earlier, DuckDB is embedded within our application, so we don’t need to set up and manage a separate database server to work with it. Instead, we can just import DuckDB in our application and we’re good to go. Additionally, DuckDB is super simple to get started with, and you don’t have to spend hours installing and configuring it.
2.2. Flexibility
DuckDB provides APIs for various languages including Python, Java, GO, and many other languages. It’s also compatible with popular data libraries such as Pandas, PyArrow, and Parquet.
2.3. SQL Support
If you work in the data field, there’s a really high probability that you’re very familiar with SQL. DuckDB fully supports SQL, and it enables us to run SQL queries on almost everything! As we will see later, with DuckDB you can run SQL queries directly on DataFrames and other common file formats such as CSV, Parquet, and JSON.
2.4. Fast
Since DuckDB is an Online Analytical Processing (OLAP) database management system, it is designed to efficiently run complex queries on large volumes of data. It also has columnar storage, which is optimized for common operations in data analysis such as aggregations and filtering.
After understanding what DuckDB is, let’s get started with it. In this tutorial we’re going to use the Python API. The first step will be to install duckDB
3. Installing DuckDB
To install duckDB run:
pip install duckdb3.1. Connecting to DuckDB
After installing duckDB, we import it in our program, then connect to it:
import duckdb
conn = duckdb.connect()duckdb.connect() returns a connection object, this connection object is our entry point to DuckDB's functionality. Let's use it to create a table in our database and insert data into it, we use sql method on the connection object to run SQL code:
conn.sql(
"""
CREATE TABLE employee(
id INTEGER PRIMARY KEY,
first_name VARCHAR,
last_name VARCHAR,
date_of_birth DATE,
salary INTEGER
)
"""
)
conn.sql(
"""
INSERT INTO employee (id, first_name, last_name, date_of_birth, salary)
VALUES
(1, 'John', 'Doe', '1990-05-15', 60000),
(2, 'Jane', 'Smith', '1985-08-25', 75000),
(3, 'Alice', 'Johnson', '1992-03-30', 55000),
(4, 'Bob', 'Brown', '1988-11-12', 80000),
(5, 'Charlie', 'Davis', '1995-07-22', 65000);
""")Let’s view the data in our table:
conn.sql("SELECT * FROM employee")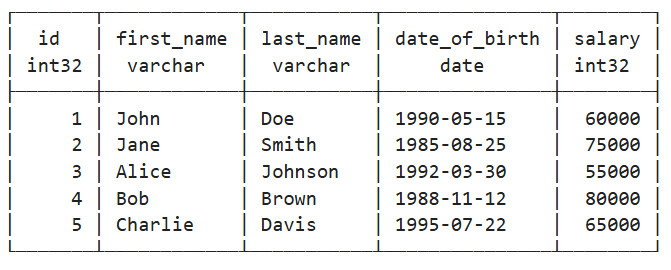
We can use to_df to get the result as a Pandas DataFrame:
emp_df = conn.sql("SELECT * FROM employee").to_df()
emp_df.head()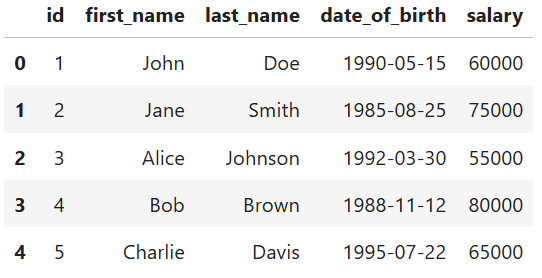
Or fetchall to get the result as a Python List:
conn.sql("SELECT * FROM employee").fetchall()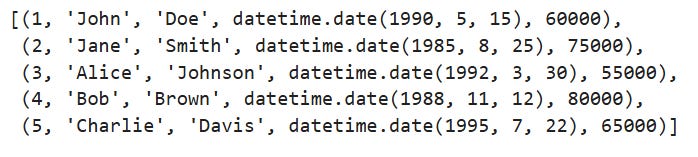
We can use conn.sql() to run various queries on our table. For example, we can view employees with a salary greater than 60000:
conn.sql("SELECT * FROM employee WHERE salary > 60000")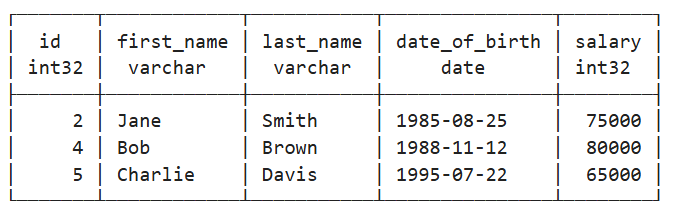
Or we can calculate the average salary:
conn.sql("SELECT AVG(salary) FROM employee")
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|