

Enhancing the reasoning abilities of Large Language Models (LLMs) is important for their application in complex tasks. This technical guide initiates a practical walkthrough for fine-tuning the Gemma 3 model specifically for reasoning, using the GRPO (General Reinforcement Pretraining Optimization) method.
As the first part in a series, this article focuses on the foundational steps required before commencing the fine-tuning loop. It provides an introduction to the GRPO algorithm, details the setup of the necessary computational environment, outlines the procedures for loading the Gemma 3 base model and tokenizer, and describes the essential steps for acquiring and preparing the target dataset. Successfully completing these stages prepares the user for the reward modeling and fine-tuning processes detailed in Part 2.

Table of Contents:
Introduction to GRPO [Part 1]
Setting Up the Working Environment [Part 1]
Loading the Model & Tokenizer [Part 1]
Loading & Preprocessing the Dataset [Part 1]
Define Reward Function [Part 2]
Model Reasoning Fine Tuning [Part 2]
Testing the Fine-Tuned Model [Part 2]
Saving the Model Locally & Hugging Face Hub [Part 2]
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Introduction to GRPO

GRPO (General Reinforcement Pretraining Optimization) is an advanced technique designed to enhance the efficiency of fine-tuning large language models.
It combines the principles of reinforcement learning with pretraining to refine the model’s behaviour using reward signals rather than direct supervision. GRPO optimizes the model’s parameters iteratively by using a policy-based optimization approach.
In a typical fine-tuning scenario, the model is trained on a supervised dataset, where it directly learns from ground truth labels. In contrast, GRPO introduces a reinforcement learning (RL) paradigm where the model is trained to maximize a reward signal that guides its behaviour.
This process allows the model to adapt more flexibly to task-specific nuances, improving both accuracy and generalization.
The key formula for policy optimization in GRPO can be expressed as:
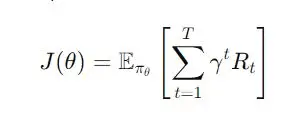
Where:

This policy-based approach ensures that the model continuously adapts to the feedback provided during training, focusing on improving the reward signal that corresponds to task-specific goals.
In GRPO, the reward function can be defined according to specific task requirements, guiding the model to focus on the desired behaviour. The reward can be a function of multiple factors, such as accuracy, formatting, or logical consistency. For instance, a correctness reward function R_correct could be defined as:

This feedback mechanism allows GRPO to progressively refine the model, emphasizing areas that matter most for the given task.
2. Setting Up the Working Environment
Before we dive into the fine-tuning Gemma 3 with GRPO, we need to ensure our environment is correctly configured with all the necessary libraries. The following code block handles the installation of essential packages:
%%capture
# Base installation for all environments
!pip install --no-deps unsloth vllm git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
# Colab-specific dependencies
import os
if "COLAB_" in "".join(os.environ.keys()):
# Clean up problematic modules to avoid restart prompts
import sys
modules = list(sys.modules.keys())
for x in modules:
if "PIL" in x or "google" in x:
sys.modules.pop(x, None)
# Install additional requirements for Colab
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft "trl==0.15.2" triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
# Install vLLM dependencies without breaking numpy
import requests, re
vllm_req = requests.get("https://raw.githubusercontent.com/vllm-project/vllm/main/requirements/common.txt").content
with open("vllm_requirements.txt", "wb") as file:
file.write(re.sub(rb"(transformers|numpy|xformers)[^\n]{1,}\n", b"", vllm_req))
!pip install -r vllm_requirements.txtLet’s break down what’s happening here:
%%capture: This is an IPython magic command used in environments like Jupyter Notebooks or Google Colab. It simply suppresses the output of the cell, keeping our notebook cleaner by hiding the potentially lengthy installation logs.
Base Installation:
!pip install — no-deps …: We install the core libraries using pip. The — no-deps flag is important here; it tells pip not to automatically install dependencies for these packages. This gives us finer control over the exact versions of dependencies, preventing potential conflicts, especially in environments like Colab, where some packages are pre-installed.
unsloth: This is a fantastic library designed to significantly speed up LLM fine-tuning and reduce memory usage, often enabling training larger models on consumer GPUs. It’s a key component for efficient fine-tuning.
vllm: A high-throughput engine for LLM inference and serving. While our focus is fine-tuning, vLLM might be useful for efficient evaluation or deployment later.
git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3: This command installs a specific version of the Hugging Face transformers library directly from their GitHub repository. The @v4.49.0-Gemma-3 part points to a branch or tag explicitly containing the necessary updates and support for the new Gemma 3 models, which might not yet be in the latest stable release on PyPI. This ensures we have the correct codebase for interacting with Gemma 3.
3. Colab-Specific Handling:
COLAB_” in “”.join(os.environ.keys()): This checks if the code is running within a Google Colab environment by looking for Colab-specific environment variables. Colab has its own pre-installed packages and behaviours, often requiring tailored setup steps.
Module Cleanup: The sys.modules.pop(…) section is a common workaround in Colab. Sometimes, pre-loaded versions of libraries (like PIL/Pillow or Google Cloud libraries) can clash with versions we intend to install, leading to errors or forcing a runtime restart. This code proactively removes potentially conflicting modules from Python’s cache before installing our specific versions, aiming for a smoother setup.
4. Additional Colab Dependencies:
bitsandbytes: Essential for enabling techniques like 4-bit quantization (QLoRA), drastically reducing the model’s memory footprint.
accelerate: A Hugging Face library that simplifies running PyTorch training scripts across different hardware configurations (CPU, single/multi-GPU, TPU) and handles mixed-precision training.
xformers: Provides memory-efficient attention mechanisms and other optimized building blocks for Transformers, often yielding speedups and memory savings. Note the specific version 0.0.29.post3 is pinned for compatibility.
peft: The Hugging Face Parameter-Efficient Fine-Tuning library. This provides methods like LoRA (Low-Rank Adaptation), which Unsloth heavily utilizes, allowing us to fine-tune massive models by only updating a small subset of parameters.
trl: The Hugging Face Transformer Reinforcement Learning library. This is crucial for our task, as it contains implementations for preference tuning algorithms like DPO (Direct Preference Optimization) and, in this context, likely the GRPO (Generalized Reinforcement Preference Optimization) method we’re focusing on. We pinned version 0.15.2.
triton, cut_cross_entropy, unsloth_zoo: These are likely lower-level dependencies or utilities used by Unsloth or other optimization libraries for custom GPU kernels and optimized operations.
sentencepiece, protobuf, datasets, huggingface_hub, hf_transfer: Standard components of the Hugging Face ecosystem for handling tokenization, data loading, and interacting with the Hugging Face Hub (downloading models/datasets, uploading results), with hf_transfer providing accelerated transfers.
5. Careful vLLM Dependency Installation: Because vLLM has its own dependencies, and we already installed specific versions of transformers and xformers, we need to be careful. This code fetches vLLM’s requirements list, uses a regular expression (re.sub) to remove the lines specifying transformers, numpy, and xformers (to avoid overwriting our specific versions or causing conflicts), saves the modified list, and then installs the remaining vLLM dependencies from that file. This ensures compatibility between all the libraries.
3. Loading the Model & Tokenizer
With our environment set up, the next crucial step is to load the Gemma 3 model itself. We’ll leverage the unsloth library here, specifically its FastModel class, which is engineered for significantly faster loading and reduced memory usage compared to standard Hugging Face methods.
Here’s the code to load the model and its corresponding tokenizer:
from unsloth import FastModel
import torch
max_seq_length = 1024
model, tokenizer = FastModel.from_pretrained(
model_name = "unsloth/gemma-3-1b-it",
max_seq_length = max_seq_length, # Choose any for long context!
load_in_4bit = False, # 4 bit quantization to reduce memory
load_in_8bit = False,
full_finetuning = False, # If you want to full fine-tune!
)We begin by importing FastModel from the unsloth library and defining our desired max_seq_length (e.g., 1024 tokens). Then, using FastModel.from_pretrained, we load the instruction-tuned unsloth/gemma-3–1b-it model.
Key parameters are set:
max_seq_length: configures the context window
load_in_4bit=False and load_in_8bit=False: specify that we are loading the model in its default precision (without quantization for now),
full_finetuning=False: enables Parameter-Efficient Fine-Tuning (PEFT) like LoRA instead of updating all model weights.
This process yields both the Unsloth-optimized model and its associated tokenizer, preparing them efficiently for the GRPO fine-tuning steps ahead.
Now that we have the base Gemma 3 model loaded, we need to prepare it for efficient fine-tuning. Instead of training all the model’s parameters (which is computationally expensive and memory-intensive), we’ll use Low-Rank Adaptation (LoRA). LoRA injects small, trainable adapter layers into the model, allowing us to achieve significant performance gains by only updating a tiny fraction of the total parameters.
Unsloth simplifies this process with the FastModel.get_peft_model method:
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.