
Fine-Tuning Llama 3.2 1B for Text2SQL: From Model Training to Production RAG Pipeline

Why Small Models Can Outperform Giants (When Done Right)?
In the rapidly evolving landscape of large language models (LLMs), the prevailing trend often favors bigger models with more parameters, promising greater performance and more generalized capabilities. However, for many practical applications, this “bigger is better” mindset can be misleading and costly.
I recently embarked on a project that challenges this conventional wisdom: fine-tuning a Llama 3.2 1B Instruct model for a text-to-SQL use case and deploying it as a production-ready RAG pipeline. As a model with a mere 1 billion parameters, this might seem like an unusual choice when compared to its much larger siblings or specialized Text2SQL models. But here’s the twist — it worked exceptionally well.
🚀 Try the live demo on Hugging Face Spaces before diving into the technical details!
2. Strategic Constraints Drive Innovation
My decision was driven by specific constraints and a unique vision. Rather than building a state-of-the-art, general-purpose text-to-SQL model capable of handling any database schema in the world, I focused on creating a specialized, highly efficient solution that could be seamlessly integrated into an RAG pipeline.
The key advantages of this approach:
Budget-Friendly: Limited GPU credits made smaller models financially viable
Faster Iteration: Quick training cycles enabled rapid experimentation
Deployment Efficiency: Lower resource requirements for production hosting
RAG Integration: Perfect size for real-time inference within retrieval pipelines
3. Dataset Engineering: Quality Over Quantity
I selected the gretelai/synthetic_text_to_sql dataset as my foundation. However, raw data rarely tells the whole story. A thorough EDA revealed significant class imbalances that could skew model performance.
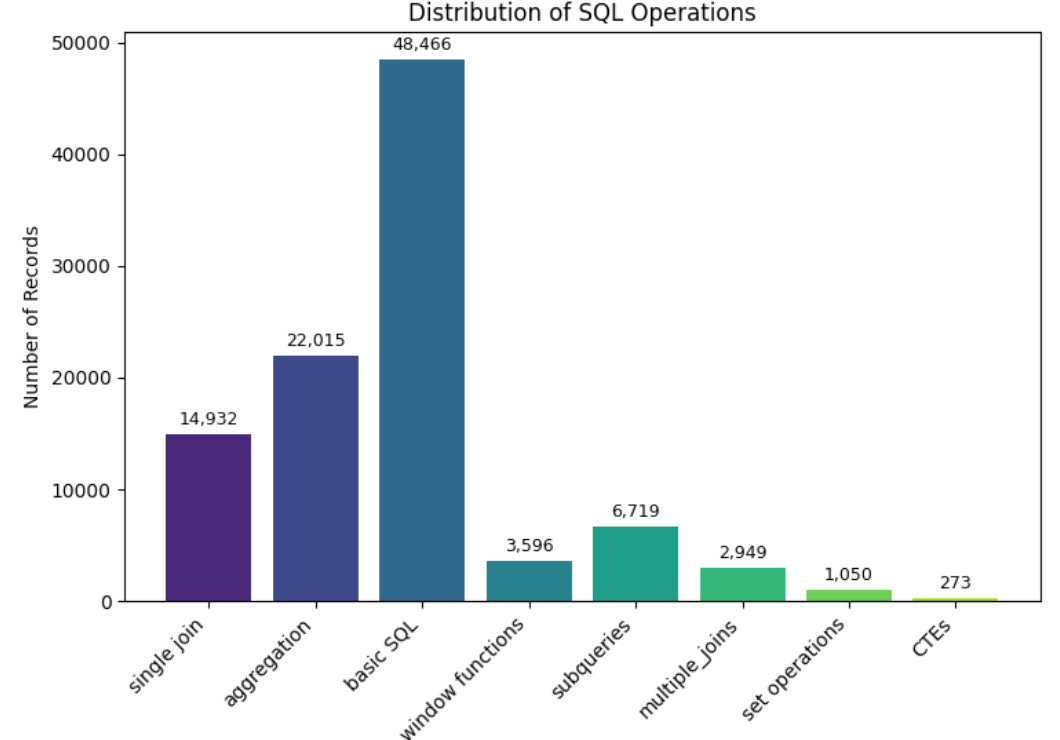
After careful analysis, I strategically focused on these five critical categories:
Single join operations
Aggregation queries
Basic SQL fundamentals
Window functions
Subqueries
This curated approach ensured balanced training across essential SQL patterns while avoiding over-representation of simple queries.
4. Data Processing Pipeline
The transformation from raw dataset to training-ready format required careful engineering:
def to_chat_template(example):
"""
Transform raw SQL data into conversational format
optimized for instruction-following models
"""
messages = [
{"role": "system", "content": example['instruction']},
{"role": "user", "content":
"**Schema and Sample Data:**" + example['sql_context'] +
"\n**Natural Language Question:**" + example['sql_prompt']},
{"role": "assistant", "content": "**SQL:**" + example['sql']}
]
return {'text': messages}
# Apply to entire dataset
dataset = dataset.map(to_chat_template)The magic happens in the tokenization step, where we prepare the data for causal language modeling:
def tokenize_fn(example):
tokenized = tokenizer(
example['text'],
truncation=True,
max_length=512, # Balanced context window
padding=False, # Dynamic padding for efficiency
return_tensors=None
)
# Critical: Labels = input_ids for next-token prediction
tokenized['labels'] = tokenized['input_ids'].copy()
return tokenized5. LoRA: Efficient Fine-Tuning Architecture
Rather than full parameter fine-tuning (which would be prohibitively expensive), I implemented LoRA (Low-Rank Adaptation) — a technique that adapts only a tiny fraction of parameters while maintaining model performance.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|