


Fine-Tuning DeepSeek R1 on Reasoning Task with Unsloth [Part 1]
Hands-On Fine-Tuning DeepSeek on Medical Reasoning Dataset

DeepSeek company recently released DeepSeek-R1, the next step in their work on reasoning models. It’s an upgrade from their earlier DeepSeek-R1-Lite-Preview and shows they’re serious about competing with OpenAI’s o1.
In this two-part hands-on tutorial, we will fine-tune the DeepSeek-R1-Distill-Llama-8B model on the Medical Chain-of-Thought Dataset from Hugging Face using Unsloth.
In the first part, we will be introduced to the DeepSeek R1 model and set the working environment, then download the model and the tokenizer and finally test the model with zero shot inference and observe the result without fine-tuning.

Table of Contents:
Introduction to DeepSeek R1 Model [Part 1]
Setting Up Working Environment [Part 1]
Loading the Model & Tokenizer with Unsloth.ai [Part 1]
Test the Model with Zero Shot Inference [Part 1]
Loading and Processing the Dataset [Part 2]
Fine — Tune the LLM [Part 2]
Model Inference After Fine-Tuning [Part 2]
Saving the model locally & Hugging Face Hub [Part 2]
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. Introduction to DeepSeek R1 Model
DeepSeek company recently released DeepSeek-R1, the next step in their work on reasoning models. It’s an upgrade from their earlier DeepSeek-R1-Lite-Preview and shows they’re serious about competing with OpenAI’s o1.
DeepSeek-R1-Zero, the first model presented in the paper DeepSeek R1 paper starts with a pretrained model called DeepSeek-V3-Base, which has 671 billion parameters.
The supervised fine-tuning stage is completely omitted. To run reinforcement learning at a large scale, instead of using standard reinforcement learning with human or AI feedback, a rule-based reinforcement learning method is employed. The reinforcement learning method used is called Group Relative Policy Optimization (GRPO), developed in-house at DeepSeek.

Given a model to train and an input problem, the input is fed into the model, and a group of outputs is sampled. Each output consists of a reasoning process and an answer.
The GRPO method observes these sampled outputs and trains the model to generate the preferred options by calculating a reward for each output using predefined rules:
Accuracy: One set of rules calculates an accuracy reward. For instance, in math problems with deterministic results, we can reliably check if the final answer provided by the model is correct. For code problems with predefined test cases, a compiler generates feedback based on the test cases.
Format: Another type of rule creates format rewards. In the below figure from the paper, we can see how the model is instructed to respond, with its reasoning process within <think> tags and the answer within <answer> tags. The format reward ensures the model follows this formatting.
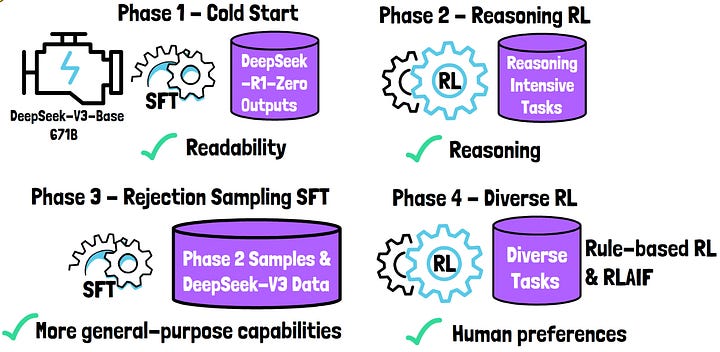
DeepSeek-R1-Zero’s outputs often suffer from poor readability and it frequently mixes languages within a single response. To address these issues, DeepSeek-R1 is trained in a four phases pipeline:
Cold Start (Phase 1): Starting with the pre-trained model DeepSeek-V3-Base, the model undergoes supervised fine-tuning on a small dataset of results collected from DeepSeek-R1-Zero. These results were validated as high-quality and readable. This dataset contains thousands of samples, making it relatively small. Incorporating a supervised fine-tuning phase on this small, high-quality dataset helps DeepSeek-R1 mitigate the readability issues observed in the initial model.
Reasoning Reinforcement Learning (Phase 2): This phase applies the same large-scale reinforcement learning we’ve reviewed for the previous model to enhance the model’s reasoning capabilities. Specifically, in tasks such as coding, math, science, and logic reasoning, where clear solutions can define rewarding rules for the reinforcement learning process.
Rejection Sampling and Supervised Fine-Tuning (Phase 3): In this phase, the model checkpoint from Phase 2 is used to generate many samples. With rejection sampling, only correct and readable samples are retained. Additionally, a generative reward model, DeepSeek-V3, is used to decide which samples should be kept. Some of DeepSeek-V3’s training data is also included in this phase. The model is then trained on this dataset using supervised fine-tuning. This dataset includes more than reasoning-oriented questions, enhancing the model’s capabilities across more domains.
Diverse Reinforcement Learning Phase (Phase 4): This final phase includes diverse tasks. Rule-based rewards are utilized for tasks that allow that, such as math. For other tasks, a LLM provides feedback to align the model with human preferences.
DeepSeek-R1 competes directly with OpenAI o1 across several benchmarks, often matching or surpassing OpenAI’s o1.

2. Setting Up Working Environment
To begin, we need to install Unsloth, an optimized library for fine-tuning large language models efficiently. The following command ensures that we install the latest version directly from GitHub:
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitThe %%capture magic command suppresses output, keeping the notebook clean. The second installation command forces a reinstallation to ensure we get the most recent updates without dependency conflicts.
Next, we authenticate with the Hugging Face Hub to access pre-trained models and datasets. We retrieve the authentication token from Google Colab’s userdata and log in using the huggingface_hub package:
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('hugging_face_space')
login(hf_token)This step allows seamless interaction with Hugging Face resources, ensuring smooth model loading and saving.
To track training experiments, we use Weights & Biases (W&B). The following code retrieves the authentication token, logs into W&B, and initializes a new experiment run:
import wandb
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B',
job_type="training",
anonymous="allow"
)This setup enables automatic tracking of metrics, logs, and hyperparameters, making it easier to monitor and analyze fine-tuning progress. Now we are ready to download the model and tokenizer and try it with zero-shot inference.
3. Loading the Model & Tokenizer with Unsloth.ai
Unsloth.ai is an innovative AI startup that optimizes the training and fine-tuning of LLMs. The platform boasts significant improvements in speed and memory usage, making it a valuable tool for AI researchers and developers. Unsloth.ai achieves these enhancements through advanced mathematical derivations and handwritten GPU kernels using OpenAI’s Triton language.
Unsloth.ai optimizes fine-tuning by manually deriving matrix differentials and performing chained matrix multiplications. This approach ensures that operations are carried out with minimal computational overhead, leading to significant performance gains. Additionally, Unsloth’s kernels are designed to be clean, readable, and highly efficient, enhancing the platform’s speed and memory usage (Unsloth).
To use Unsloth, users can load their model with the FastLanguageModel.from_pretrained function, specify the desired configurations, and begin fine-tuning. The platform supports various model architectures and offers pre-quantized 4-bit models to facilitate faster downloads and reduced memory fragmentation.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.