


Building Multimodal RAG Application #1: Introduction

Welcome to the Building Multimodal Retrieval-Augmented Generation (RAG) Application series which will offer a hands-on introduction to building a question-answering system for interacting with multimodal data, particularly video collections.
In this series of articles, the following topics will be covered:
Introduction to Multimodal RAG Applications (You are here!)
Multimodal RAG Application Architecture (Coming soon!)
Multimodal Embeddings (Coming soon!)
Processing Videos for Multimodal RAG (Coming soon!)
Multimodal Retrieval from Vector Stores (Coming soon!)
Large Vision Language Models (LVLMs) (Coming soon!)
Multimodal RAG with Multimodal LangChain (Coming soon!)
Putting it All Together! Building Multimodal RAG Application (Coming soon!)
The codes and datasets used for this series will be on this GitHub Repo

My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. What is RAG?
RAG is an advanced technique that enhances the capabilities of language models by combining the strengths of information retrieval and text generation. It works by retrieving relevant external documents or data points and feeding them into a generative model (like GPT) to create more informed, accurate, and contextually rich responses.

RAG applications consist mainly of two steps:
Retrieval: When a user asks a question, a retrieval mechanism (often a vector search using embeddings) fetches relevant documents or pieces of information from a large corpus or database.
Generation: The retrieved information is then passed as input to a generative model that uses this context to craft a detailed and coherent response.
RAG systems are particularly powerful because they don’t rely solely on the generative model’s internal knowledge, which might be outdated or limited. Instead, they leverage real-time, up-to-date information from external sources to provide more accurate answers.
Applications of RAG:
Open-domain question answering: RAG models can answer queries using external knowledge sources, like a document database, improving accuracy.
Customer support: Automatically responding to customer inquiries using relevant knowledge base articles.
Summarization: RAG can be used to summarize content from retrieved documents based on a specific user query.
2. What is Multimodal RAG?
Multimodal Retrieval-Augmented Generation (Multimodal RAG) extends the RAG framework to handle not just text but multiple data modalities — like images, audio, video, and more. The goal is to build systems that can answer complex queries that involve diverse types of data, making the system far more versatile.
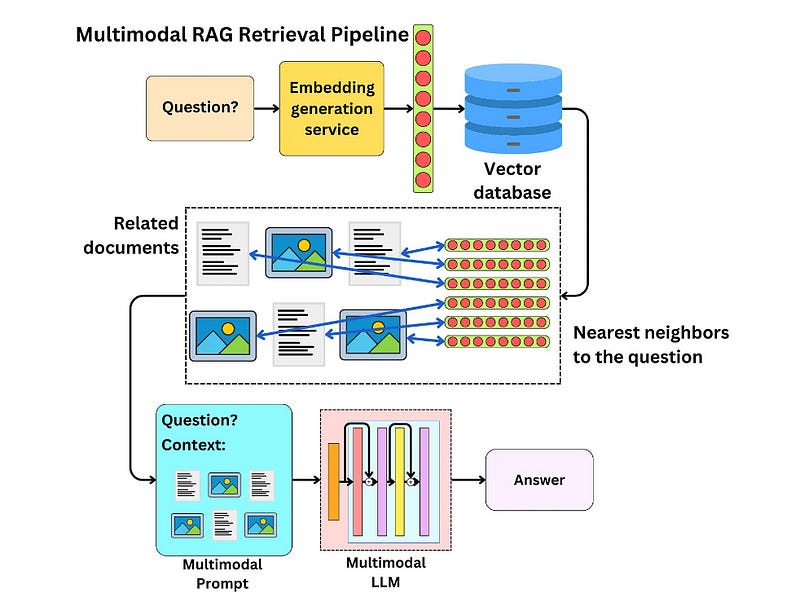
Key Components:
Multimodal Embeddings: The system uses models that can encode data from different modalities (e.g., images, text, audio) into a common semantic space. This allows the system to understand and relate information across modalities.
Retrieval: When a user asks a multimodal query (e.g., a text question about a video), the system retrieves relevant content from a database that could include text documents, images, or specific video frames.
Generation: Once relevant content is retrieved, it is fed into a multimodal generative model (like a vision-language model) that processes both the text and visual content to generate a response.
For example, a multimodal RAG system could be used to answer a query like: “What’s happening in the video when the speaker talks about machine learning?” It would retrieve relevant video segments, process both the visual and textual data, and generate a detailed response.
Tools and Models:
Multimodal Transformers: Models like BridgeTower or CLIP are capable of encoding and merging visual and textual information into joint embeddings.
Vector Databases: These databases store multimodal embeddings and help in retrieving content that matches a given query across different modalities.
Whisper Model: Used for transcribing video or audio data, making it accessible for text-based retrieval.
LangChain: A framework that facilitates building pipelines for RAG applications by handling retrieval, text processing, and interaction with large language models.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Great work Youssif, very informative articles.
Note: try to review and update articles URLs in the content index.