

Multimodal retrieval-augmented generation (RAG) is transforming how AI applications handle complex information by merging retrieval and generation capabilities across diverse data types, such as text, images, and video.
Unlike traditional RAG, which typically focuses on text-based retrieval and generation, multimodal RAG systems can pull in relevant content from both text and visual sources to generate more contextually rich, comprehensive responses.
This article, the sixth installment in our Building Multimodal RAG Applications series, dives into inference with Large Vision Language Models (LVLMs) within an RAG framework.
We’ll cover setting up the environment, preparing data, and leveraging LVLMs across a variety of use cases. These include tasks like image captioning, visual question answering, and querying images based on embedded text or associated captions and transcripts, showcasing the full potential of LVLMs to unlock advanced multimodal interactions.

This article is the sixth in the ongoing series of Building Multimodal RAG Application:
Large Vision Language Models (LVLMs) (You are here!)
Multimodal RAG with Multimodal LangChain (Coming soon!)
Putting it All Together! Building Multimodal RAG Application (Coming soon!)
You can find the codes and datasets used in this series in this GitHub Repo
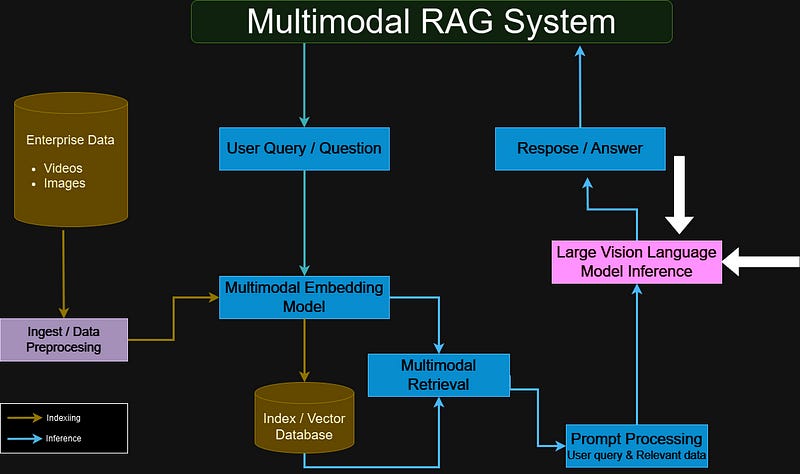
Table of Contents:
Setting-Up Working Environment
Data Preparation
LVLMs Use Cases
3.1. Image Captioning
3.2. Visual Questioning & Answering
3.3. Questioning & Answering on Textual Cues on Images
3.4. Questioning & Answering on Caption/Transcript Associated with Images
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Setting-Up Working Environment
The first step in this tutorial is to import the packages we will use in this article. Path from the pathlib module is used to work with file paths in a platform-independent way, making it easier to navigate directories and manage file paths consistently across different operating systems.
The urlretrieve function from the urllib.request module allows you to download files directly from a URL, which is particularly useful for retrieving online images or datasets.
The Image module from the PIL (Pillow) library is a powerful tool for opening, manipulating, and saving image files in various formats, supporting operations like resizing, filtering, and enhancing images.
Finally, display from IPython.display enables the inline display of images in Jupyter notebooks, allowing images to be rendered immediately within the notebook environment for easier visualization and debugging during data exploration or computer vision tasks.
from pathlib import Path
from urllib.request import urlretrieve
from PIL import Image
from IPython.display import display
Next, we will load three helper functions that we will be using in this article. The first function, encode_image, encodes an image either from a given file path or from a PIL Image object into a base64 string, which is useful for transmitting images as text data.
First, it checks if the input is a PIL Image using isinstance. If it is, the function saves this image temporarily in memory using a BytesIO buffer in JPEG format.
The buffered image data is then encoded into base64 format and returned as a UTF-8 decoded string, making it suitable for embedding or transmission over text-based protocols.
If the input is instead a file path, the function opens the file in binary read mode, reads its contents, encodes the binary data directly into base64, and returns the decoded string. This flexibility allows the function to handle both in-memory images and images saved on disk, streamlining image encoding workflows.
# encoding image at given path or PIL Image using base64
def encode_image(image_path_or_PIL_img):
if isinstance(image_path_or_PIL_img, PIL.Image.Image):
# this is a PIL image
buffered = BytesIO()
image_path_or_PIL_img.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
else:
# this is a image_path
with open(image_path_or_PIL_img, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')The next helper function is the lvlm_inference_with_conversation function which performs language model inference within a conversational context using the Prediction Guard platform.
First, it retrieves a Prediction Guard client via _getPredictionGuardClient(), which is likely a helper function that authenticates and initializes the client.
The function then extracts the conversation history by calling conversation.get_message(), which gathers all messages exchanged between the user and the assistant.
With this message history, the function calls the chat.completions.create method on the Prediction Guard client to generate a response. Key parameters are specified for the model, including “llava-1.5–7b-hf” as the model ID, max_tokens to limit the token count of the response, temperature for controlling response creativity, top_p for nucleus sampling, and top_k for further token filtering.
Finally, the function returns the latest generated message content from the response, allowing this output to be used as the assistant’s reply in the conversation.
def lvlm_inference_with_conversation(conversation, max_tokens: int = 200, temperature: float = 0.95, top_p: float = 0.1, top_k: int = 10):
# get PredictionGuard client
client = _getPredictionGuardClient()
# get message from conversation
messages = conversation.get_message()
# call chat completion endpoint at Grediction Guard
response = client.chat.completions.create(
model="llava-1.5-7b-hf",
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
top_k=top_k,
)
return response['choices'][-1]['message']['content']Finally, we will create a prediction_guard_llava_conv which is an instance of the Conversation class, configured to manage interactions between a user and an assistant in a conversational AI context.
The system parameter is set to an empty string, indicating no predefined system message, while roles specify the conversation participants as “user” and “assistant.”
The messages list is initialized as empty, ready to store conversation history, and the version tag describes this setup as “Prediction Guard LLaVA endpoint Conversation v0” for version control or identification.
The sep_style is set to SeparatorStyle.SINGLE, meaning that each message will be separated by a single divider style, which aids in parsing conversation turns.
Lastly, map_roles maps the “user” and “assistant” roles to custom labels “USER” and “ASSISTANT,” potentially standardizing how these roles are referenced in logs or outputs. Together, these configurations help define the structure and style of interaction between the user and assistant in this conversational setup.
prediction_guard_llava_conv = Conversation(
system="",
roles=("user", "assistant"),
messages=[],
version="Prediction Guard LLaVA enpoint Conversation v0",
sep_style=SeparatorStyle.SINGLE,
map_roles={
"user": "USER",
"assistant": "ASSISTANT"
}
)Now that we have the working environment ready we will load and prepare the data.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.