

In the second article of the Building Multimodal RAG Application series, we explore the process of building a multimodal retrieval-augmented generation (RAG) application using multimodal embeddings.
We start by providing an overview of multimodal embeddings, explaining how they bridge different data types, such as text and images, by embedding them into a shared vector space.
Next, we introduce the Bridge Tower model, a state-of-the-art solution for computing these embeddings. The guide then walks through the process of setting up your work environment and computing multimodal embeddings for both text and images.
We will also cover techniques for measuring the similarity between these embedding vectors, crucial for cross-modal retrieval tasks. Finally, we demonstrate how to visualize high-dimensional embeddings using UMAP, enabling a deeper understanding of the structure and relationships within the data.
This comprehensive guide will equip you with the tools and knowledge to build a multimodal RAG system, enhancing your ability to work with text-image interactions.
This article is the second in the ongoing series of Building Multimodal RAG Application:
Multimodal Embeddings (You are here!)
Multimodal RAG Application Architecture (Coming soon!)
Processing Videos for Multimodal RAG (Coming soon!)
Multimodal Retrieval from Vector Stores (Coming soon!)
Large Vision Language Models (LVLMs) (Coming soon!)
Multimodal RAG with Multimodal LangChain (Coming soon!)
Putting it All Together! Building Multimodal RAG Application (Coming soon!)
You can find the codes and datasets used in this series in this GitHub Repo
Table of Contents:
Overview of Multimodal Embeddings
Overview of the Bridge Tower Model
Setting up Work Environment
Compute Multimodal Embeddings
Measure Similarity Between Embedding Vectors
Visualizing High-dimensional Data with UMAP
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Overview of Multimodal Embeddings
Embedding is a vector that is densely packed with semantic information about the thing we aim the represent. Think of it as a way to capture the meaning, and context, of our data (image, text, audio) in a way that allows us to do math with them.
In this series, we will use the Bridge Tower embedding model (will be introduced below) to create embedding vectors of image text pairs as you can see in Figure 1.

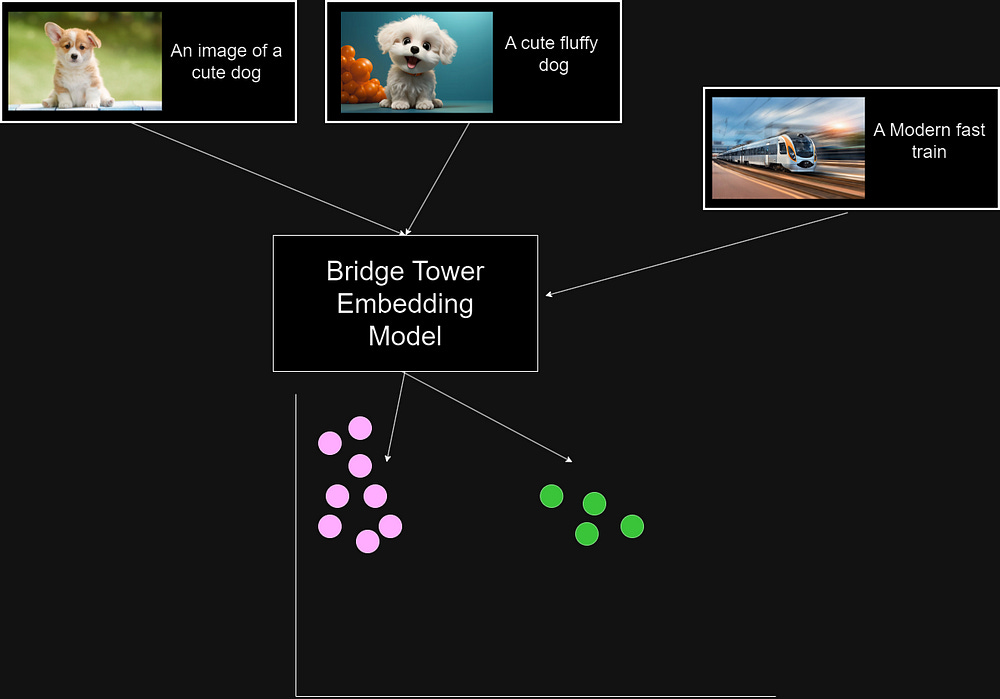
In Figure 2, images of dogs and a train are paired with their corresponding text descriptions, such as “A cute dog” or “A modern fast train.” The model projects these inputs into a shared embedding space, where representations of similar concepts are grouped closely together.
For instance, the text and images related to dogs form a cluster in the embedding space, indicating that the model recognizes the semantic similarity between them, regardless of the modality (text or image).
On the other hand, the train image and its description are clustered separately, reflecting a distinct concept. This clustering highlights how multimodal embedding models, like Bridge Tower, align different types of data — text and images — by mapping them to a common vector space, enabling tasks like cross-modal retrieval or matching.
2. Overview of the Bridge Tower Model
To generate multimodal embeddings from the text image pairs we will use the bridge tower multimodal embedding model. The BridgeTower model was proposed in BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, and Nan Duan.
The goal of this model is to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.

The model consists of three types of encoders:
Text Encoder: It takes our text data as inputs and they generate those dense vectors called embeddings. In this case, we will call them text embeddings.
Visual Encoder: It processes visual data such as images into dense embeddings. In this case, we will call them visual embeddings.
Cross-Modal Encoder: It is a key component in multimodal embedding models, which are designed to process and integrate information from different modalities, such as text, images, audio, and video. In these models, the cross-modal encoder bridges the gap between different types of data (modalities) by learning joint representations that capture relationships between them.
3. Setting up Work Environment
We will start with importing the libraries and packages we will be using throughout this article. Here is a brief description of the imported packages:
jsonandos: For handling file I/O and configurations.numpyandnorm: For numerical operations and vector norms, likely for similarity calculations.cv2(OpenCV): For image processing and feature extraction.UMAP: For dimensionality reduction, high-dimensional data (e.g., image features) can be projected into a lower-dimensional space.MinMaxScaler: To scale features to a specific range (e.g., [0, 1]).pandas: For data manipulation, probably managing tabular data like image labels or feature vectors.tqdm: To display progress bars for long-running tasks, like iterating over large datasets.
import json
import os
import numpy as np
from numpy.linalg import norm
import cv2
from umap import UMAP
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
from tqdm import tqdmThen we will define three helper functions that we will use through this article. The first two are the bt_embedding_from_prediction_guard() and the get_prediction_guard_api_key. They are used to interact with Prediction Guard API to compute joint embeddings of a text prompt and a base64-encoded image, using a Bridge Tower model for multimodal embeddings.
def get_prediction_guard_api_key():
load_env()
PREDICTION_GUARD_API_KEY = os.getenv("PREDICTION_GUARD_API_KEY", None)
if PREDICTION_GUARD_API_KEY is None:
PREDICTION_GUARD_API_KEY = input("Please enter your Prediction Guard API Key: ")
return PREDICTION_GUARD_API_KEY
PREDICTION_GUARD_URL_ENDPOINT = os.getenv("DLAI_PREDICTION_GUARD_URL_ENDPOINT", "https://dl-itdc.predictionguard.com") ###"https://proxy-dl-itdc.predictionguard.com"
# helper function to compute the joint embedding of a prompt and a base64-encoded image through PredictionGuard
def bt_embedding_from_prediction_guard(prompt, base64_image):
# get PredictionGuard client
client = _getPredictionGuardClient()
message = {"text": prompt,}
if base64_image is not None and base64_image != "":
if not isBase64(base64_image):
raise TypeError("image input must be in base64 encoding!")
message['image'] = base64_image
response = client.embeddings.create(
model="bridgetower-large-itm-mlm-itc",
input=[message]
)
return response['data'][0]['embedding']The third helper function is the encode_image which we will use to encode an image (either a file path or a PIL image) into a base64-encoded string, which can then be easily transmitted as text in the prediction guarded API requests.
# encoding image at given path or PIL Image using base64
def encode_image(image_path_or_PIL_img):
if isinstance(image_path_or_PIL_img, PIL.Image.Image):
# this is a PIL image
buffered = BytesIO()
image_path_or_PIL_img.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
else:
# this is a image_path
with open(image_path_or_PIL_img, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')Finally, we will define a set of image text pairs that we will use for visualization and explanation purposes. This set will consist of three image text pairs as you can see below.
import requests
from PIL import Image
from IPython.display import display
# You can use your own uploaded images and captions.
# You will be responsible for the legal use of images that
# you are going to use.
url1='http://farm3.staticflickr.com/2519/4126738647_cc436c111b_z.jpg'
cap1='A motorcycle sits parked across from a herd of livestock'
url2='http://farm3.staticflickr.com/2046/2003879022_1b4b466d1d_z.jpg'
cap2='Motorcycle on a platform to be worked on in garage'
url3='http://farm1.staticflickr.com/133/356148800_9bf03b6116_z.jpg'
cap3='a cat lying down stretched out near a laptop'
img1 = {
'flickr_url': url1,
'caption': cap1,
'image_path' : './shared_data/motorcycle_1.jpg'
}
img2 = {
'flickr_url': url2,
'caption': cap2,
'image_path' : './shared_data/motorcycle_2.jpg'
}
img3 = {
'flickr_url' : url3,
'caption': cap3,
'image_path' : './shared_data/cat_1.jpg'
}
# download images
imgs = [img1, img2, img3]
for img in imgs:
data = requests.get(img['flickr_url']).content
with open(img['image_path'], 'wb') as f:
f.write(data)
for img in [img1, img2, img3]:
image = Image.open(img['image_path'])
caption = img['caption']
display(image)
display(caption)
print()Example 1: A motorcycle sits parked across from a herd of livestock

Example 2: Motorcycle on a platform to be worked on in the garage

Example 3: a cat lying down stretched out near a laptop

Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.