
Building Multimodal RAG Application #8: Putting it All Together! Building Multimodal RAG Application

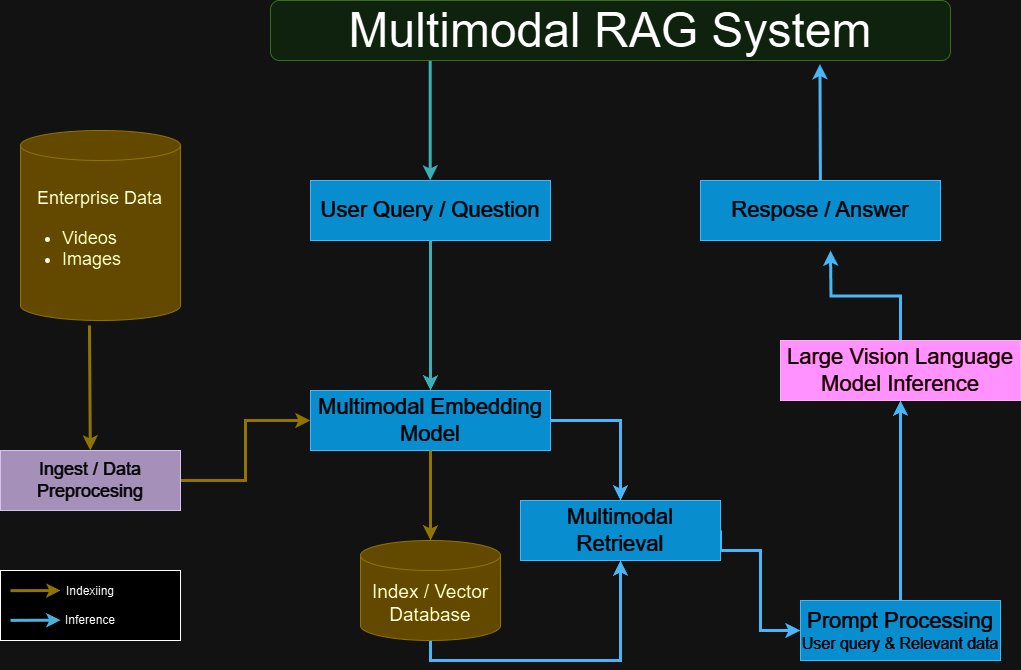
Multimodal retrieval-augmented generation (RAG) is transforming how AI applications handle complex information by merging retrieval and generation capabilities across diverse data types, such as text, images, and video.
Unlike traditional RAG, which typically focuses on text-based retrieval and generation, multimodal RAG systems can pull in relevant content from both text and visual sources to generate more contextually rich, comprehensive responses.
This article, the eighth and last part of our Building Multimodal RAG Applications series, wraps up all the modules we have built in the previous articles and puts them into one place.
We’ll cover setting up the environment, preparing the data in the preprocessing module, retrieving the relevant video frames in the multimodal retrieval module, leveraging LVLMs across a variety of use cases in the LVLM inference and prompt processing modules, and finally putting all these modules together and building a multimodal RAG system with LangChain.
This article is the eighth in the ongoing series of Building Multimodal RAG Application:
Putting it All Together! Building Multimodal RAG Application (You are here!)
You can find the codes and datasets used in this series in this GitHub Repo
Table of Contents:
Setting Up Working Environment
Preprocessing Module
Multimodal Retrieval Module
LVLM Inference Module
Prompt Processing Module
Multimodal RAG System with LangChain
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Setting Up Working Environment
Let's start setting up the working environment as usual by installing and importing the required packages. We will start by installing the predictionguard package to use their API.
!pip install predictionguardNext, we will import some of the general packages we will use in most modules and define a function to load the API key of the prediction guard.
import os
from PIL import Image
from dotenv import load_dotenv
def get_prediction_guard_api_key():
load_env()
PREDICTION_GUARD_API_KEY = os.getenv("PREDICTION_GUARD_API_KEY", None)
if PREDICTION_GUARD_API_KEY is None:
PREDICTION_GUARD_API_KEY = input("Please enter your Prediction Guard API Key: ")
return PREDICTION_GUARD_API_KEYNow that we are ready to go through the modules that we built in the previous article of this series.
2. Preprocessing Module
The first module we will put together is the preprocessing module we built in the second and fourth articles. This module will process the multimodal data, extract the caption for each frame, generate multimodal embeddings, and finally put them together. We will start by defining helper functions.
import base64
from io import BytesIO
from PIL import Image
from typing import Union
from predictionguard import PredictionGuard
# encoding image at given path or PIL Image using base64
def encode_image(image_path_or_PIL_img):
if isinstance(image_path_or_PIL_img, PIL.Image.Image):
# this is a PIL image
buffered = BytesIO()
image_path_or_PIL_img.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
else:
# this is a image_path
with open(image_path_or_PIL_img, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# checking whether the given string is base64 or not
def isBase64(sb):
try:
if isinstance(sb, str):
# If there's any unicode here, an exception will be thrown and the function will return false
sb_bytes = bytes(sb, 'ascii')
elif isinstance(sb, bytes):
sb_bytes = sb
else:
raise ValueError("Argument must be string or bytes")
return base64.b64encode(base64.b64decode(sb_bytes)) == sb_bytes
except Exception:
return False
# get PredictionGuard Client
def _getPredictionGuardClient():
PREDICTION_GUARD_API_KEY = get_prediction_guard_api_key()
client = PredictionGuard(
api_key=PREDICTION_GUARD_API_KEY,
url=PREDICTION_GUARD_URL_ENDPOINT,
)
return client
def bt_embedding_from_prediction_guard(prompt, base64_image):
# get PredictionGuard client
client = _getPredictionGuardClient()
message = {"text": prompt,}
if base64_image is not None and base64_image != "":
if not isBase64(base64_image):
raise TypeError("image input must be in base64 encoding!")
message['image'] = base64_image
response = client.embeddings.create(
model="bridgetower-large-itm-mlm-itc",
input=[message]
)
return response['data'][0]['embedding']Next, we will define the BridgeTowerEmbeddings class to create multimodal embeddings.
from typing import List
from langchain_core.embeddings import Embeddings
from langchain_core.pydantic_v1 import (
BaseModel,
)
from utils import encode_image, bt_embedding_from_prediction_guard
from tqdm import tqdm
class BridgeTowerEmbeddings(BaseModel, Embeddings):
""" BridgeTower embedding model """
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed a list of documents using BridgeTower.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
embeddings = []
for text in texts:
embedding = bt_embedding_from_prediction_guard(text, "")
embeddings.append(embedding)
return embeddings
def embed_query(self, text: str) -> List[float]:
"""Embed a query using BridgeTower.
Args:
text: The text to embed.
Returns:
Embeddings for the text.
"""
return self.embed_documents([text])[0]
def embed_image_text_pairs(self, texts: List[str], images: List[str], batch_size=2) -> List[List[float]]:
"""Embed a list of image-text pairs using BridgeTower.
Args:
texts: The list of texts to embed.
images: The list of path-to-images to embed
batch_size: the batch size to process, default to 2
Returns:
List of embeddings, one for each image-text pairs.
"""
# the length of texts must be equal to the length of images
assert len(texts)==len(images), "the len of captions should be equal to the len of images"
embeddings = []
for path_to_img, text in tqdm(zip(images, texts), total=len(texts)):
embedding = bt_embedding_from_prediction_guard(text, encode_image(path_to_img))
embeddings.append(embedding)
return embeddingsNow let's initialize a BridgeTower embedded instance from the class we have just created.
# initialize an BridgeTower embedder
embedder = BridgeTowerEmbeddings()Now that the preprocessing module is ready the next step is to build the multimodal retrieval module.
