
Building MCP-Powered Agentic RAG Application: Step-by-Step Guide (2/2)

While many tutorials show how to build Retrieval-Augmented Generation (RAG) systems by connecting a language model to a single database, this approach is often too limited.
This guide takes you to the next level with Agentic RAG, where you won’t just build a system that retrieves information — you’ll build one that intelligently decides where to look. It’s the difference between an AI that can only read one assigned book and an AI that knows exactly which book to pull from the library.
To achieve this, we will use the Model Context Protocol (MCP), a modern framework designed specifically for creating powerful, multi-tool AI agents. In this step-by-step tutorial, we will walk you through the entire process:
Setting up a complete MCP server.
Defining custom tools for both private data and live web searches.
Constructing a full RAG pipeline that puts the agent in control.
By the end, you’ll have a fully functional and intelligent application capable of fielding complex queries by dynamically sourcing the best possible context for a truly accurate answer.
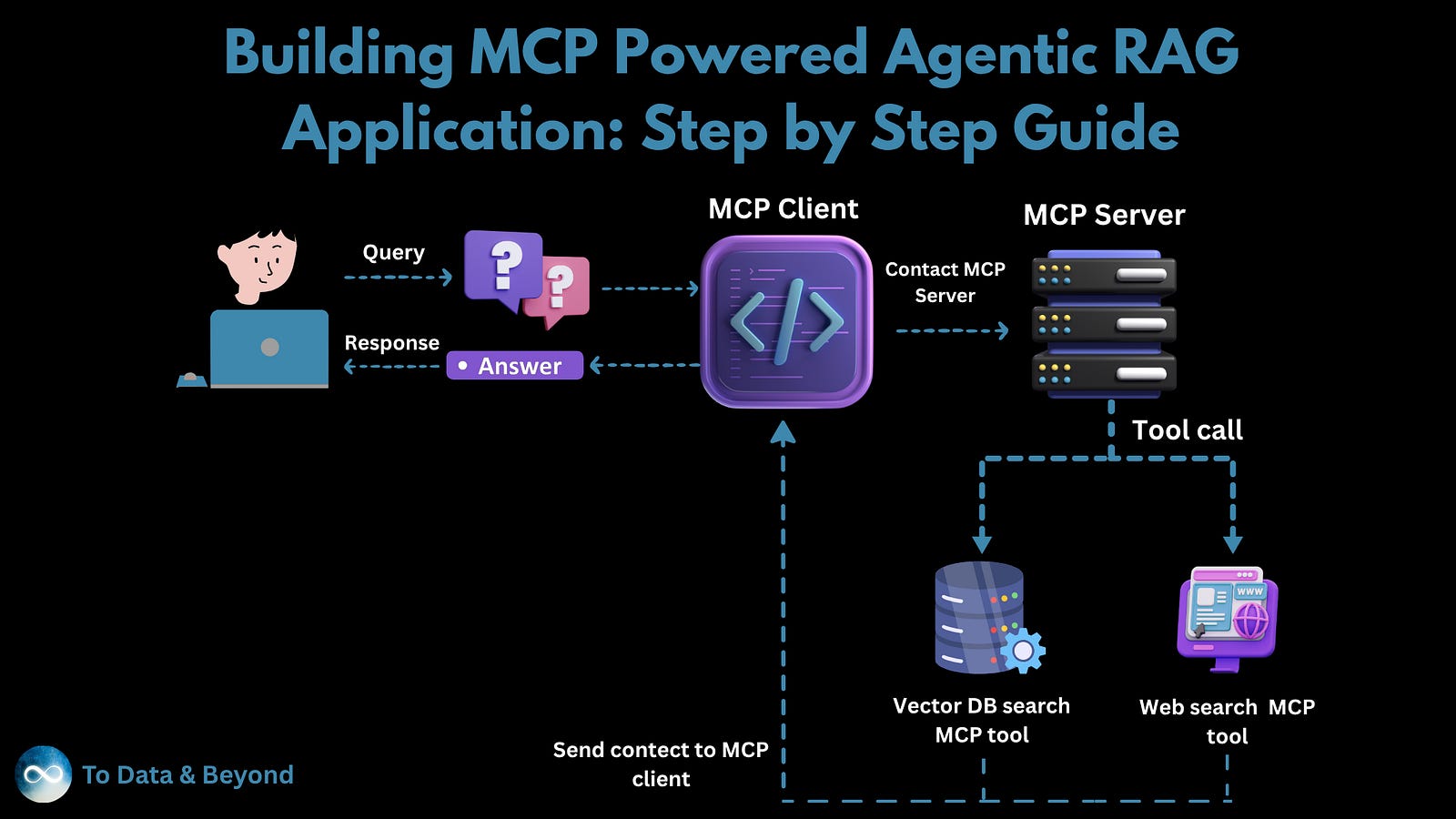
Table of Contents:
Define MCP Tools
Building RAG Pipeline
Putting Everything Together and Testing the System
You can find the codes used in this article in this GitHub Repository!
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
5. Define MCP Tools
Our MCP server is now instantiated, but it’s like a skilled worker with an empty toolbox. To make it useful, we need to give it tools. In the MCP world, a tool is simply a Python function that we “register” with the server, making it a capability the agent can choose to use. This registration is done with a simple decorator: @mcp_server.tool().
Crucially, the agent relies on the function’s docstring to understand what the tool does and when it should be used. A well-written docstring is not just for developers; it’s a direct instruction to the AI, guiding its decision-making process.
Let’s start by defining our first tool: the one that connects to our private vector database. This tool will be responsible for searching our internal Python FAQ knowledge base.
Add the following code to your mcp_server.py file.
@mcp_server.tool()
def python_faq_retrieval_tool(query: str) -> str:
"""
Retrieve the most relevant documents from the Python FAQ collection.
Use this tool when the user asks about general Python programming concepts.
Args:
query (str): The user query to retrieve the most relevant documents.
Returns:
str: The most relevant documents retrieved from the vector DB.
"""
if not isinstance(query, str):
raise TypeError("Query must be a string.")
# Use the single, pre-initialized faq_engine instance for efficiency
return faq_engine.answer_question(query)Let’s break down this powerful piece of code:
@mcp_server.tool(): This is the magic decorator. It tells our mcp_server instance, “Hey, here is a new capability you can use!” The server automatically inspects the function’s name, its parameters, and — most importantly — its docstring to learn about this new skill.
The Docstring: This is the most critical part for the agentic behavior. When the agent receives a user query, it will read this description to decide if this tool is the right one for the job. We’ve explicitly told it to use this tool when the user asks about general Python programming concepts. This clear instruction is what allows the agent to distinguish between needing to search our internal FAQ versus, say, searching the web.
python_faq_retrieval_tool(query: str) -> str: This is a standard Python function with type hints. The MCP framework uses these hints to validate inputs and understand the data types the tool works with.
faq_engine.answer_question(query): This is the line that executes the tool’s core logic. It calls a method on an faq_engine object (which we will build in the “Building RAG Pipeline” section) to perform the actual vector search in our Qdrant database and return the results as a string.
With this single function, we’ve given our agent its first sense — the ability to look up information in its own specialized memory. Next, we’ll give it the ability to look outward to the web.
Now, what if the user asks about a very recent Python library, a current event, or a topic not covered in our internal knowledge base? For that, our agent needs to be able to browse the internet.
We’ll equip our agent with a second tool that uses the FireCrawl API to perform a live web search. This gives our agent a way to find real-time, public information, making it vastly more versatile.
Add the final tool to your mcp_server.py:
@mcp_server.tool()
def firecrawl_web_search_tool(query: str) -> List[str]:
"""
Search for information on a given topic using Firecrawl.
Use this tool when the user asks a specific question not related to the Python FAQ.
Args:
query (str): The user query to search for information.
Returns:
List[str]: A list of the most relevant web search results.
"""
if not isinstance(query, str):
raise TypeError("Query must be a string.")
url = "https://api.firecrawl.dev/v1/search"
api_key = os.getenv('FIRECRAWL_API_KEY')
if not api_key:
return ["Error: FIRECRAWL_API_KEY environment variable is not set."]
payload = {"query": query, "timeout": 60000}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
# Assuming the API returns JSON with a key like "data" or "results"
# Adjust .get("data", ...) if the key is different
return response.json().get("data", ["No results found from web search."])
except requests.exceptions.RequestException as e:
return [f"Error connecting to Firecrawl API: {e}"]This firecrawl_web_search_tool function is another powerful capability for our agent. Registered with the same @mcp_server.tool() decorator, its docstring provides the critical instruction for when it should be used: for any question not related to the Python FAQ.
This creates a clear distinction from our first tool, enabling the agent to make an intelligent choice. The function’s logic is straightforward: it securely retrieves the Firecrawl API key from our environment variables, constructs a POST request containing the user’s query, and sends it to the Firecrawl API.
To ensure our application is resilient and doesn’t crash on network failures, the entire API call is wrapped in a try…except block, allowing it to handle connection issues gracefully. Upon a successful request, it parses the JSON response and returns a list of search results, effectively giving our agent access to the vast information of the internet.
With both tools now defined, our agent has a choice: look inward into its private knowledge base or look outward to the public web. Next, we will build the engine that powers our internal knowledge search.
6. Building RAG Pipeline
Our python_faq_retrieval_tool is currently just a promise; it relies on an faq_engine object to do the heavy lifting of vector search, but we haven’t built this engine yet. This component is the heart of the “Retrieval” part of our RAG system. It will be responsible for two critical tasks:
