
Building Image-to-Text Matching System Using Hugging Face Open-Source Models

Building an image-to-text matching system using Hugging Face’s open-source models involves understanding several key concepts and steps. The process starts with an introduction to multimodal models, highlighting their importance and applications. It then focuses on the image-text retrieval task, discussing its relevance and challenges.
The guide details setting up the working environment, including installing necessary libraries and dependencies and explains the procedures for loading the model and processor using Hugging Face’s transformers library. It covers the preparation of image and text data to ensure correct processing and formatting for the model. Finally, it demonstrates how to perform image-text matching and interpret the results effectively.
By leveraging Hugging Face’s open-source models, the guide offers comprehensive insights into developing robust image-to-text matching systems, making it a valuable resource for researchers and practitioners in the field of multimodal AI.

Table of Contents:
Introduction to Multimodal Models
Introduction to Image-Text Retrieval Task
Setting Up Working Environment
Loading the Model and Processor
Preparing the Image and Text
Performing Image-Text Matching
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Introduction to Multimodal Models
When a task requires a model to take more than one type of data, such as an image and a sentence, we call it multimodal. Multimodal models are designed to handle and integrate different forms of input, like text, images, audio, and even video, to perform a variety of tasks.
These models are increasingly important in applications that require a deep understanding of complex data, such as image captioning, visual question answering (VQA), and multimodal content creation.
One prominent example of a multimodal model is ChatGPT with GPT-4. This model allows users to send text, images, and even audio, making it a versatile tool for a wide range of applications.
GPT-4 can understand and generate human-like text, and when enhanced with multimodal capabilities, it can also interpret images and audio, offering responses that are contextually relevant across different types of data.
Multimodal models have numerous applications across various fields:
Image Captioning: Generating descriptive captions for images by understanding the content within them.
Visual Question Answering (VQA): Answering questions about the contents of an image by combining natural language processing with computer vision.
Text-to-Image Generation: Creating images based on textual descriptions, useful in creative industries and design.
Speech Recognition and Synthesis: Converting speech to text and vice versa, enhancing communication tools and accessibility.
Augmented Reality (AR) and Virtual Reality (VR): Integrating multiple data types to create immersive and interactive experiences.
In this article, we will explore one of these tasks which is image-text retrieval or matching. In the coming articles of this series, we will cover the rest of these topics.
2. Introduction to Image-Text Retrieval Task
The Image-Text Retrieval task, also known as image-text matching, is a significant challenge in the field of computer vision and natural language processing (NLP). This task involves determining the relevance or similarity between an image and a piece of text.
It can be broadly divided into two subtasks: retrieving the most relevant images given a textual query (text-to-image retrieval) and retrieving the most relevant text descriptions given an image (image-to-text retrieval).
The model will output if the text matches the image. For example, if we pass a photo of a man and a dog and the input text is “the man in the blue shirt is wearing glasses,” the model should return that the text does not match the image.
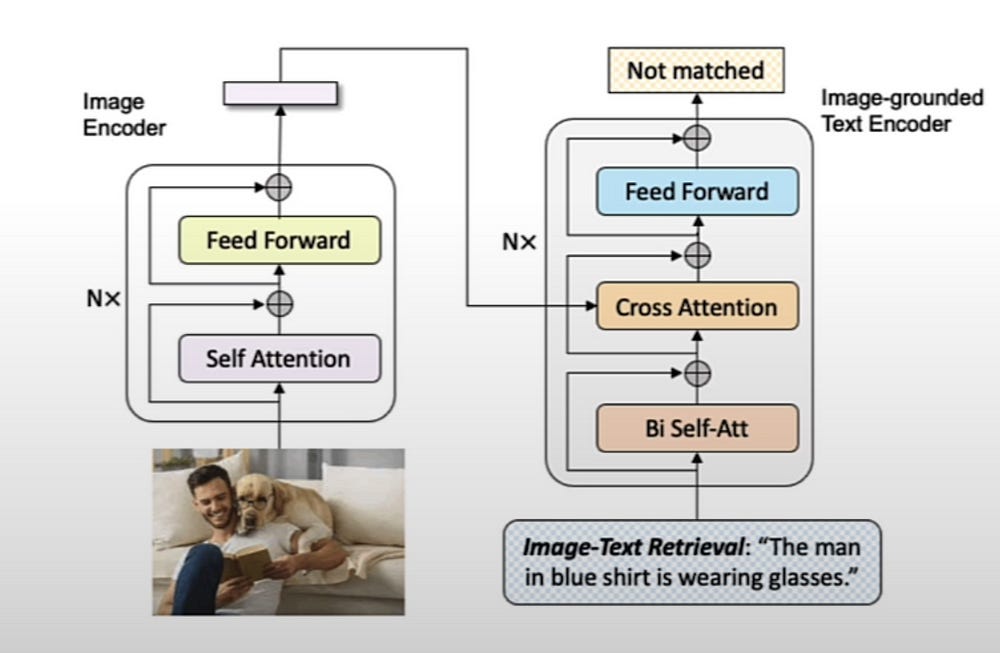
3. Setting Up Working Environment
Let’s start by setting up the working environments. First, we will download the packages we will use in this article. We will download the Transformers package and the torch package to use Pytorch.
!pip install transformers
!pip install torch4. Loading the Model and Processor
We will need to load the model and the processor to perform the task. First, to load the model, we need to import the BleepForImageTextRetrieval class from the Transformers library.
Then, to load the model, you just need to call the class we imported and use the from_pretrained method to load the checkpoint. We will use the Bleep model from Salesforce for this task, and this is the related checkpoint for this specific task.
from transformers import BlipForImageTextRetrieval
model = BlipForImageTextRetrieval.from_pretrained(
"./models/Salesforce/blip-itm-base-coco")As for the processor, it’s practically the same. We need to import the AutoProcessor class from Transformers. To load the correct processor, we use the from_pretrained method and pass the related checkpoint. The processor’s role is to process the image and the text for the model.
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(
"./models/Salesforce/blip-itm-base-coco")Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.