

At this current phase of AI evolution, any model with fewer than 1 billion parameters can be called a small language model. If we look at our past models like GPT-3 which has ~175 billion parameters, and when we think about GPT-4, it is heard that it might contain 1 trillion parameters.
As per the scaling law, it says that as parameters increase, the performance of the model increases. So, of course, we can infer from here that having a large universe architecture can give better results, but what if a small architecture model can give better results than a larger model architecture?
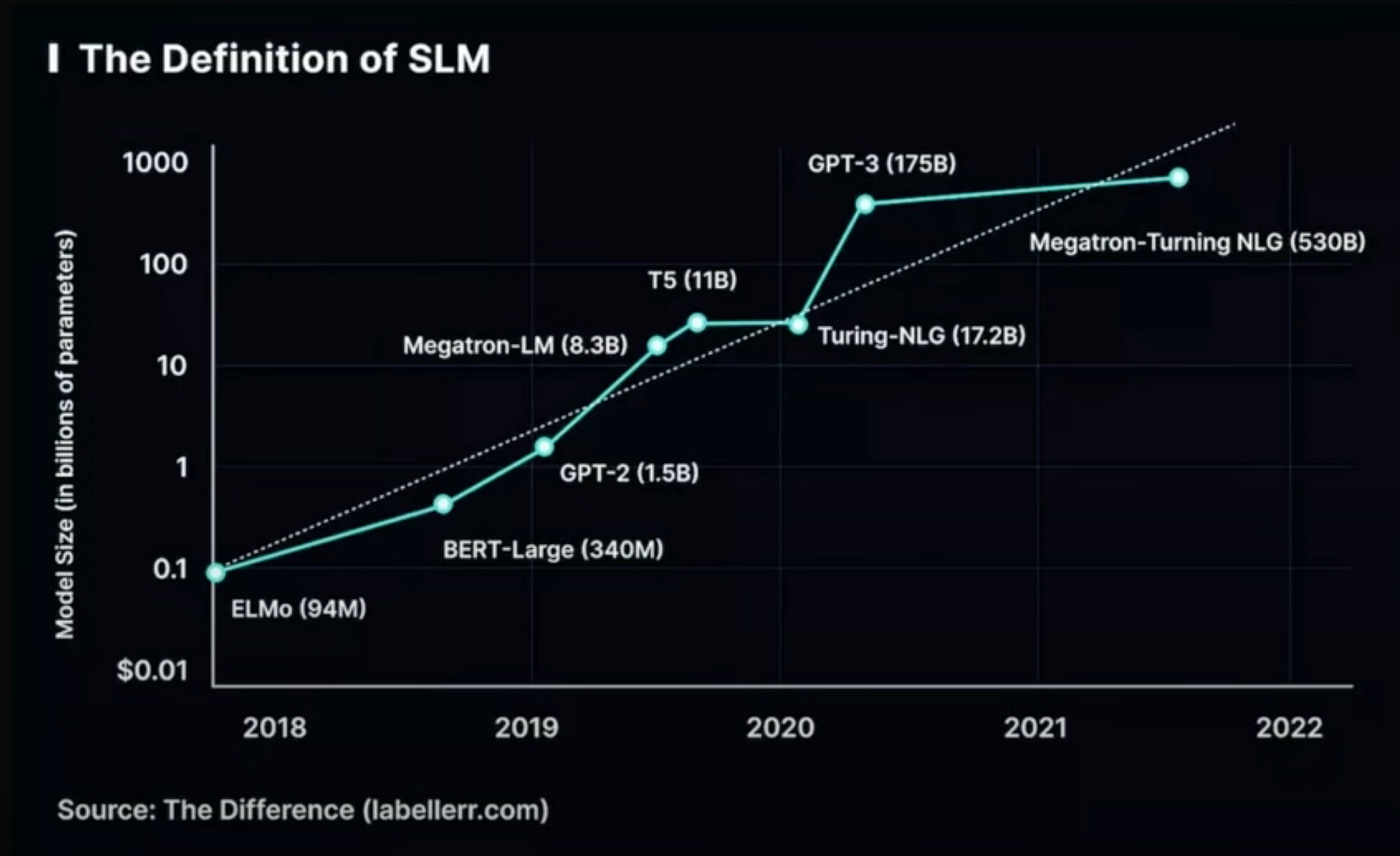
Can we construct a language model with just 10–15 M parameters that produces coherent text?
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
The complete training pipeline is here :
Part 1: Our dataset
We select and take a tiny dataset. TinyStories is a synthetic dataset of short stories that only contain words that a typical 3 to 4-year-old usually understands, generated by GPT-3.5 and GPT-4. We can get it from HuggingFace.
!pip install datasets
from datasets import load_dataset
ds = load_dataset("roneneldan/TinyStories")
Our dataset looks like this, with every row corresponding to a story. There are 2 million such rows for training and 20000 such rows for validation. Our dataset looks like this, with every row corresponding to a story. There are 2 million such rows for training and 20000 such rows for validation.
Part 2: Data pre-processing (Tokenization, Input-Output Pairs)
Let us take a small example from our dataset, and our goal is to do 2 things: 1) Tokenize the dataset — we will use the GPT-2 sub-word tokenizer. 2) Store all token IDs in a single .bin file.
Take input data and convert it into a numerical format.
We will take every single story and have each token mapped to a token ID for each of the story words, and then merge all these token IDs into a very big corpus of token IDs. This will be training data.
For example story — this could be tokens and ids. Tokens are stored in a dictionary format with IDs and length.

Similarly, for all stories, we will have different dictionaries like this with token IDs and lengths, and we will merge all these together and save them in .bin format in a local saved storage.
Why do we use disk storage?
1. Installing and Importing Libraries
https://github.com/openai/tiktoken
!pip install tiktoken # Installs the tiktoken library for tokenization
import tiktoken # GPT(-2/3/4) compatible token encoding/decoding
import os # For filesystem operations
import numpy as np # Numerical operations / memmap arrays
from tqdm.auto import tqdm # Progress bars for loops2. Tokenizer Initialization
enc = tiktoken.get_encoding("gpt2") # Load the GPT-2 encoding scheme (Byte-Pair Encoding)This tokenizer, used by GPT-2/3/4, converts raw text to integer “tokens.”
3. Tokenization Function
def process(example):
ids = enc.encode_ordinary(example['text']) # Encode to token IDs (no special tokens)
out = {'ids': ids, 'len': len(ids)}
return outInput: dictionary with an
'text'entry (one document/sample).Output: dictionary with:
'ids': List of token ids (integers)'len': Number of tokens
4. Tokenizing the Dataset
if not os.path.exists("train.bin"):
tokenized = ds.map(
process,
remove_columns=['text'],
desc="tokenizing the splits",
num_proc=8,
)Checks for existing (“train.bin”) file — avoids redundant work.
ds.map:
Applies
processto every text sample in the dataset (ds)Removes the original ‘text’ column
Uses multiple processors for speed (
num_proc=8)Adds progress label
5. Saving Tokenized Data to Binary Files
for split, dset in tokenized.items():
arr_len = np.sum(dset['len'], dtype=np.uint64)
filename = f'{split}.bin'
dtype = np.uint16 # Safe, as GPT-2 token values < 65536
arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
total_batches = 1024
idx = 0
for batch_idx in tqdm(range(total_batches), desc=f'writing {filename}'):
batch = dset.shard(num_shards=total_batches, index=batch_idx, contiguous=True).with_format('numpy')
arr_batch = np.concatenate(batch['ids'])
arr[idx : idx + len(arr_batch)] = arr_batch
idx += len(arr_batch)
arr.flush()This code is part of the data preprocessing pipeline that enables training of transformer models efficiently on large text datasets.
For each split (train, val, etc.):
Computes total token count for that split.
Prepares a large binary file (
*.bin) using numpy.memmap for efficiency.Batches writing for speed and memory (1,024 shards).
Loops over each batch; fetches the batch’s tokens as numpy arrays.
Writes the sequential batch token IDs to the memory-mapped array.
Flushes the memmap file to disk at the end.
Summary & What This Is For
Purpose: Converts a text dataset into GPT-style token IDs and stores them sequentially in fast binary files, optimized for training neural LMs like GPT.
Why Batches: Efficient I/O and memory usage on large datasets.
Why memmap: Handles datasets larger than RAM by mapping files directly in memory.
Why np.uint16: Token IDs (max 50256 for GPT-2) fit into 16 bits, so it saves space.
We need to split the dataset into batches and add everything to “train.bin”.
To quickly summarize:
Every story is broken into a bunch of token IDs
Every token ID has some length associated with it
Store all these Token IDs need to be place in some place
This place is called train.bin, and this file needs to be saved on the disk instead of RAM
train.bin will contain all token IDs together.
(1) Tokenize the dataset into tokenIDs.
(2) Create a file called “train.bin” and “validation.bin” where we will store the tokenIDs from the entire dataset.
(3) We make sure the tokenIDs are stored on a disk, rather than on the RAM for efficient computations.
Part-3: Create Input-Output batches for the dataset
Now, let us create the input-output pairs from the dataset
Let's assume the context size is 4 tokens, and also the batch size is 4 (x1, x2, x3, x4). The output tensor for each input x1 is y1, which is the same as the input but shifted by right side of the text by 1 token.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|