
Analyzing the Architecture of GPT-OSS

Large Language Models (LLMs) have evolved significantly since GPT-2. GPT-OSS brings several key architectural improvements that enhance efficiency, scalability, and overall performance. In this blog, we’ll break down these changes step by step, comparing them to older approaches and explaining why they matter.
This is the first time since GPT-2 that OpenAI has made a large language model fully open-weighted, meaning all of its parameters are publicly accessible. Over the past few days, I’ve studied the code and technical reports to highlight the most interesting and important insights.
Table of Contents:
Model Architecture Overview
Coming From GPT-2
Removing Dropout
RoPE Replaces Absolute Positional Embeddings
Swish/SwiGLU Replaces GELU
Mixture-of-Experts (MoE) Replaces the Single FeedForward Module
Grouped Query Attention Replaces Multi-Head Attention
Sliding-Window Attention
RMSNorm Replaces LayerNorm
The GPT-2 Legacy
Conclusion: Why GPT-OSS Matters
20k Subscribers Celebration: $130 Worth of Value for Just $20

To Data & Beyond just reached a big milestone — 20,000 subscribers!
1. Model Architecture Overview
Before we discuss the architecture in more detail, let’s start with an overview of the two models, gpt-oss-20b and gpt-oss-120b.
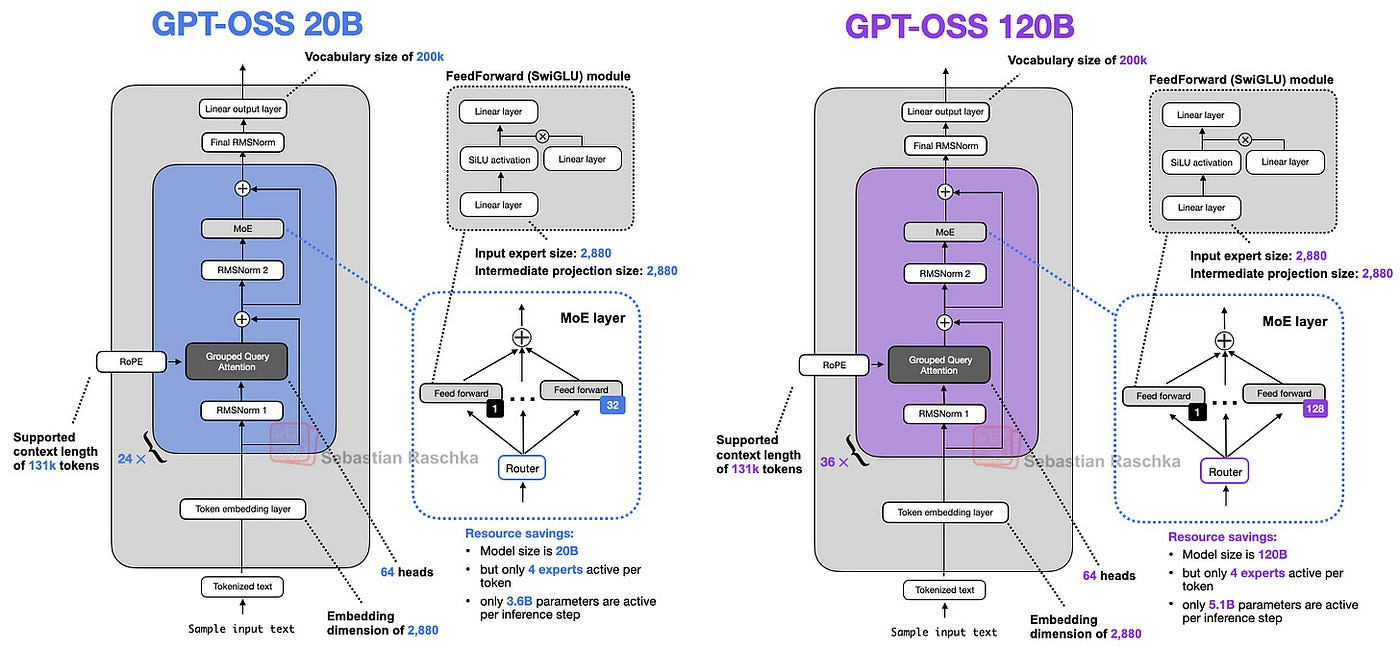
At its core, GPT-OSS is still a decoder-only transformer, just like the original GPT family — but with some serious upgrades to make it both smarter and leaner at scale.
OpenAI has released it in two main sizes:
gpt-oss-120b — the heavyweight reasoning champ (117B total params, 5.1B active per token), runs on a single 80 GB GPU like the NVIDIA H100 or AMD MI300X thanks to smart quantization.
gpt-oss-20b — a smaller, lower-latency version (21B total, 3.6B active) that’s easier to run locally or for specialized fine-tunes.
Both share the same architectural DNA:
36 Transformer blocks stacked in sequence.
Multi-Head Attention with Grouped Query Attention (64 attention heads, but only 8 key/value heads) to cut memory use without hurting quality.
Mixture-of-Experts (MoE) MLPs with 128 experts, but only the top 4 are active for each token
SwiGLU activations for smoother learning.
RMSNorm for faster, simpler normalization.
Sliding-window attention in alternating layers for efficiency at long contexts.
2. Coming From GPT-2
Before directly jumping towards GPT-OSS, let’s first take a look at GPT-2, so we can better understand how much the architecture has evolved.
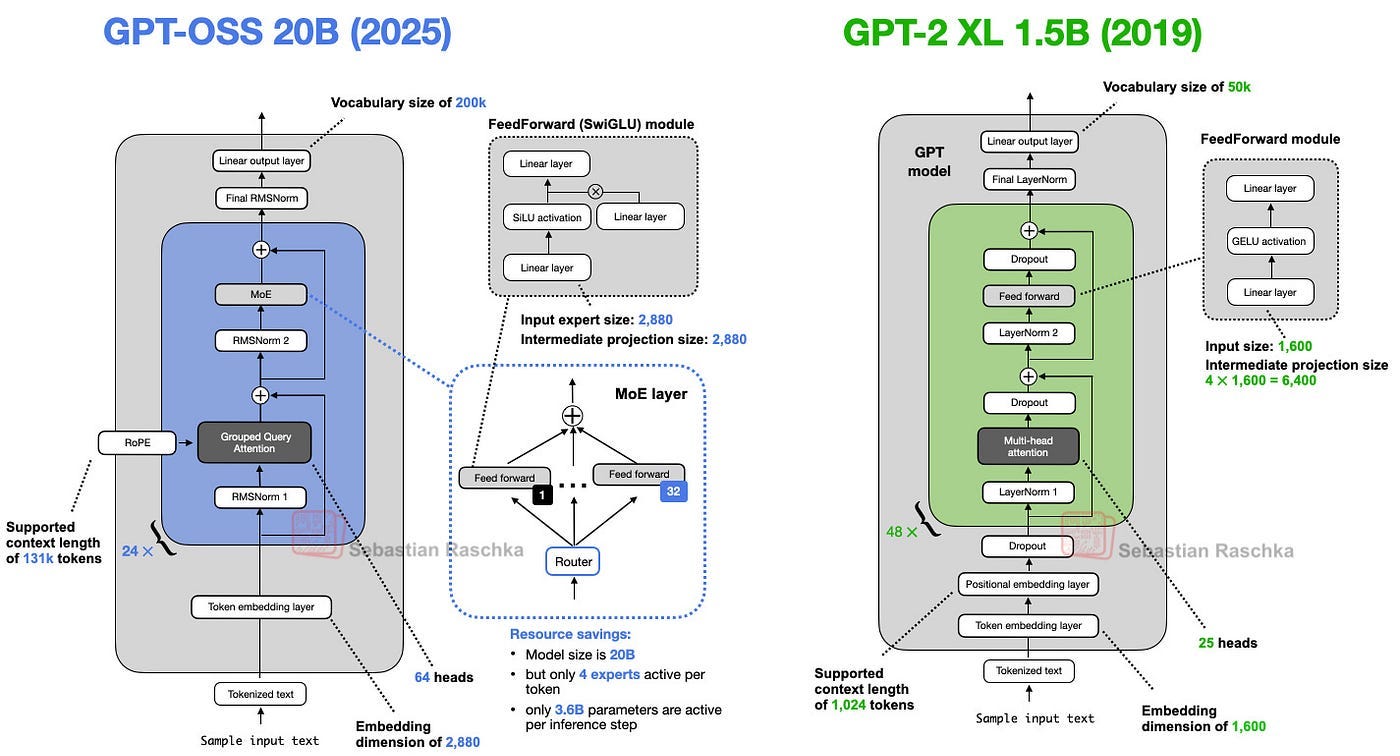
Both GPT-oss and GPT-2 are decoder-only LLMs built on the transformer architecture introduced in the Attention Is All You Need (2017) paper. Over the years, many details have evolved.
Let’s break down the above two pictures:
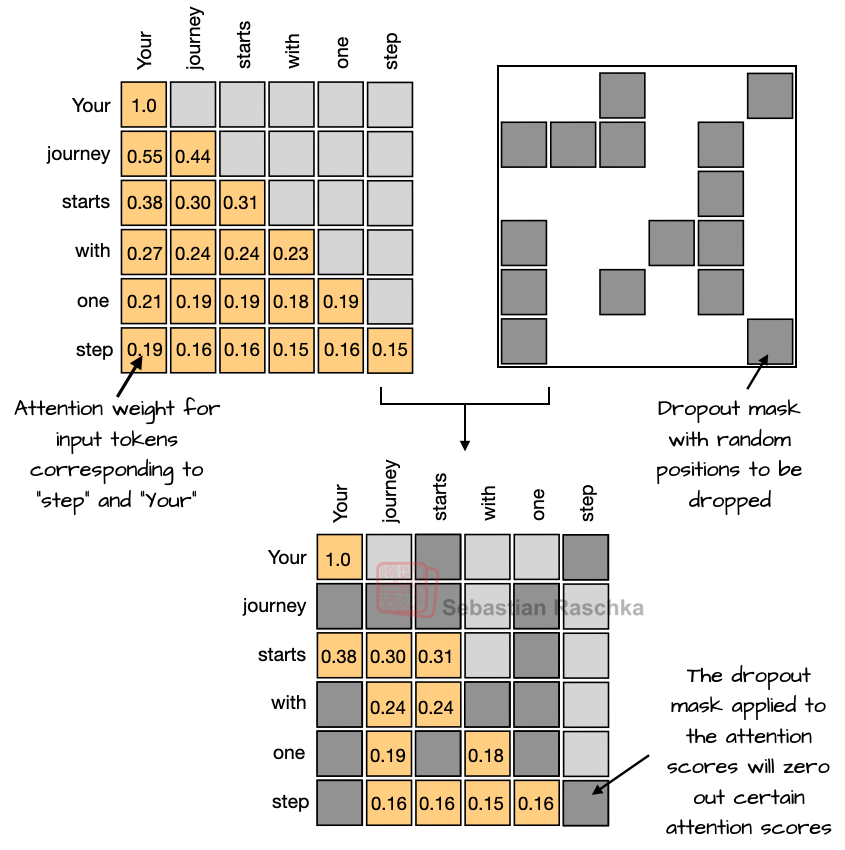
2.1 Removing Dropout
Dropout (2012) is a method to stop a model from overfitting. It works by randomly turning off some neurons (setting their values to zero) during training. But in modern large language models, dropout is hardly used anymore — in fact, most models after GPT-2 stopped using it.
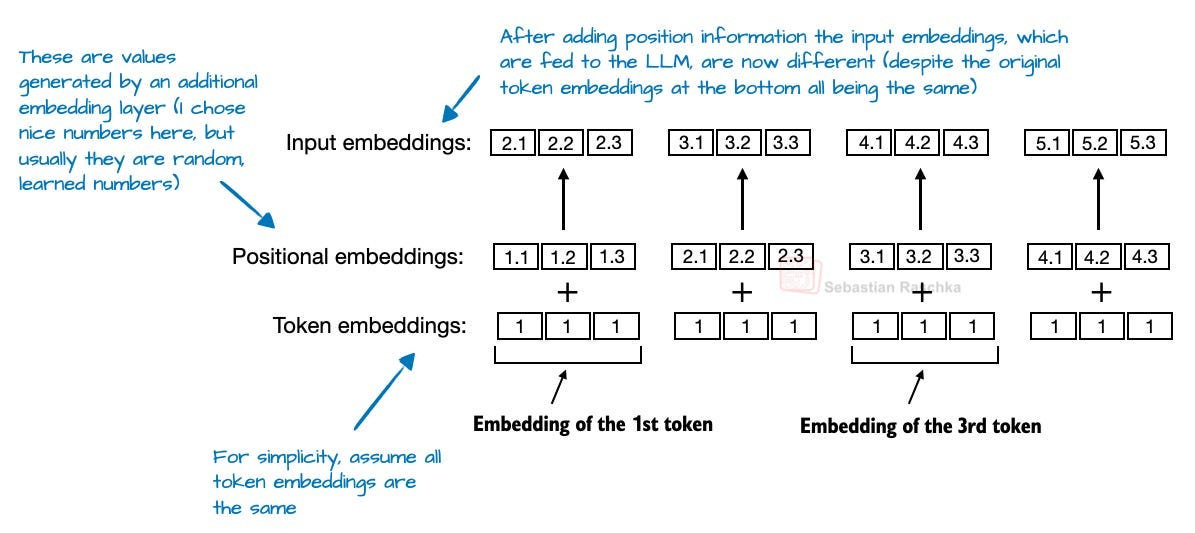
2.2 RoPE Replaces Absolute Positional Embeddings
In transformer-based LLMs, positional encoding is necessary because of the attention mechanism. By default, attention treats the input tokens as if they have no order. In the original GPT architecture, absolute positional embeddings addressed this by adding a learned embedding vector for each position in the sequence, which is then added to the token embeddings.
1. Why Attention Needs Position Information
The self-attention mechanism computes similarity between tokens purely from embeddings.
Without positional encoding, “He likes cats” and “Cats like him” would look identical to the model, because the bag of tokens is the same.
Thus, attention alone captures relationships, but not order.
Example:
Input tokens:
A, B, C.Attention sees them as just three vectors in a set {A, B, C}, with no clue whether the original order was
A B CorC B A.
2. original GPT (absolute positional embeddings)
GPT adds a learned embedding vector for each position (1, 2, 3, … up to max sequence length).
So token embedding = word embedding + position embedding.
This lets the model distinguish between “dog” at position 1 vs “dog” at position 5.
Visualize:
Word: “dog” → vector
[0.1, -0.2, …].Pos(1):
[0.05, 0.03, …].Final embedding =
[0.15, -0.17, …].
3. Limitations of Absolute Positional Embeddings
Fixed length: you must predefine the maximum context length (e.g., 1024 for GPT-2).
Generalization issue: if you train on sequences of length ≤1024, the model struggles with longer sequences, since position embeddings beyond 1024 are unseen.
Inefficiency: storing large embedding tables for positions is memory-heavy.
4. Transition to Relative Positioning (RoPE in GPT-OSS)
Absolute embeddings only say “this is token #37.”
But what matters for language understanding is relative distance:
In “He likes cats”, the distance between “He” and “cats” is 2.
In longer sequences, absolute IDs like #37 or #205 don’t really matter, but their offset does.
RoPE encodes positions via rotations in vector space, so relative differences are directly baked into dot-products during attention.
2.3 Swish/SwiGLU Replaces GELU
In earlier GPT models, the activation function of choice was GELU (Gaussian Error Linear Unit). Activation functions decide how much signal passes through a neuron, and they add the non-linearity that makes deep learning possible.
Now, GPT-OSS replaces GELU with Swish (also called SiLU) and sometimes its gated variant, SwiGLU.
Swish = smoother ReLU
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|