


A Landscape of Advanced AI Models: Architectures, Capabilities, and Applications
A Landscape of Advanced AI Models: Architectures, Capabilities, and Applications

The field of Artificial Intelligence is experiencing an unprecedented surge in innovation, particularly in the development of sophisticated model architectures.
Navigating this rapidly evolving landscape of acronyms and capabilities — from Large Language Models (LLMs) to Segment Anything Models (SAMs) — can be daunting.
This article serves as a comprehensive guide, demystifying a selection of these state-of-the-art architectures. We delve into Large Language Models (LLMs), Large Concept Models (LCMs), Vision-Language Models (VLMs), Small Language Models (SLMs), Mixture of Experts (MoE) frameworks, Masked Language Models (MLMs), Large Action Models (LAMs), and Segment Anything Models (SAMs).
For each model type, this post breaks down its core definition, key architectural components, operational mechanics, and significant real-world applications, offering readers a clear understanding of these transformative technologies.

Table of Contents:
LLMs (Large Language Models)
LCMs (Large Concept Models)
VLMs (Vision-Language Models)
SLMs (Small Language Models)
MoE (Mixture of Experts)
MLMs (Masked Language Models)
LAMs (Large Action Models)
SAMs (Segment Anything Models)
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLMs (Large Language Models)

Large Language Models (LLMs) are a type of artificial intelligence model designed to understand, generate, and manipulate human language at an unprecedented scale.
They are “large” due to their immense number of parameters (from billions to trillions) and the vast datasets (often terabytes of text and code) they are trained on. This scale allows them to capture complex patterns, nuances, and knowledge embedded within human language.
The core architecture behind most modern LLMs is the Transformer, which utilizes a mechanism called “self-attention.” This allows the model to weigh the importance of different words in an input sequence when processing information, enabling it to understand context over long passages.

LLMs are typically pre-trained on a massive corpus of text using self-supervised learning objectives, like predicting the next word in a sentence or filling in masked words. This pre-training phase imbues them with general linguistic capabilities, after which they can be fine-tuned for specific tasks.
LLMs work by taking an input text (a prompt) and generating a coherent and contextually relevant continuation or response. During inference, the model predicts the next word (or token) based on the input and previously generated words, repeating this process autoregressive.
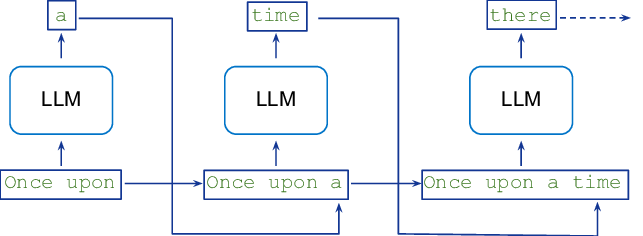
LLM applications are incredibly diverse, including advanced chatbots and virtual assistants (like ChatGPT), content creation (writing articles, poetry, code), machine translation, text summarization, question answering, and sentiment analysis. They are fundamentally changing how humans interact with information and technology.
2. LCMs (Large Concept Models)
Large Concept Models (LCMs) represent an evolution or a specialized focus beyond purely text-based LLMs, aiming to understand and reason about the world through a richer representation of concepts and their relationships.
While LLMs learn implicitly about concepts from text, LCMs aim to make this knowledge more explicit and structured, potentially integrating knowledge graphs, ontologies, or symbolic reasoning components. The goal is to move beyond pattern matching in text towards a deeper, more human-like conceptual understanding.

The main components of an LCM might include a powerful language understanding module (likely an LLM at its core), a knowledge base (which could be learned or curated), and reasoning engines.
These components would work together to build and query a dynamic model of concepts and their interconnections. For instance, an LCM might not just know that “Paris” is the capital of “France,” but also understand the concept of a capital city, its typical attributes, and how it relates to other geographical, political, and cultural concepts.

LCMs work by processing information (text, and potentially other modalities in the future) to identify key concepts, link them to existing knowledge, and infer new relationships.
This allows for more robust reasoning, better handling of ambiguity, and improved common-sense understanding. While still an emerging area, potential applications include advanced question-answering systems that can explain their reasoning, scientific discovery by identifying novel connections between concepts, more reliable fact-checking, and building AI systems that can learn and adapt more like humans by forming and refining conceptual models of their environment.
3. VLMs (Vision-Language Models)
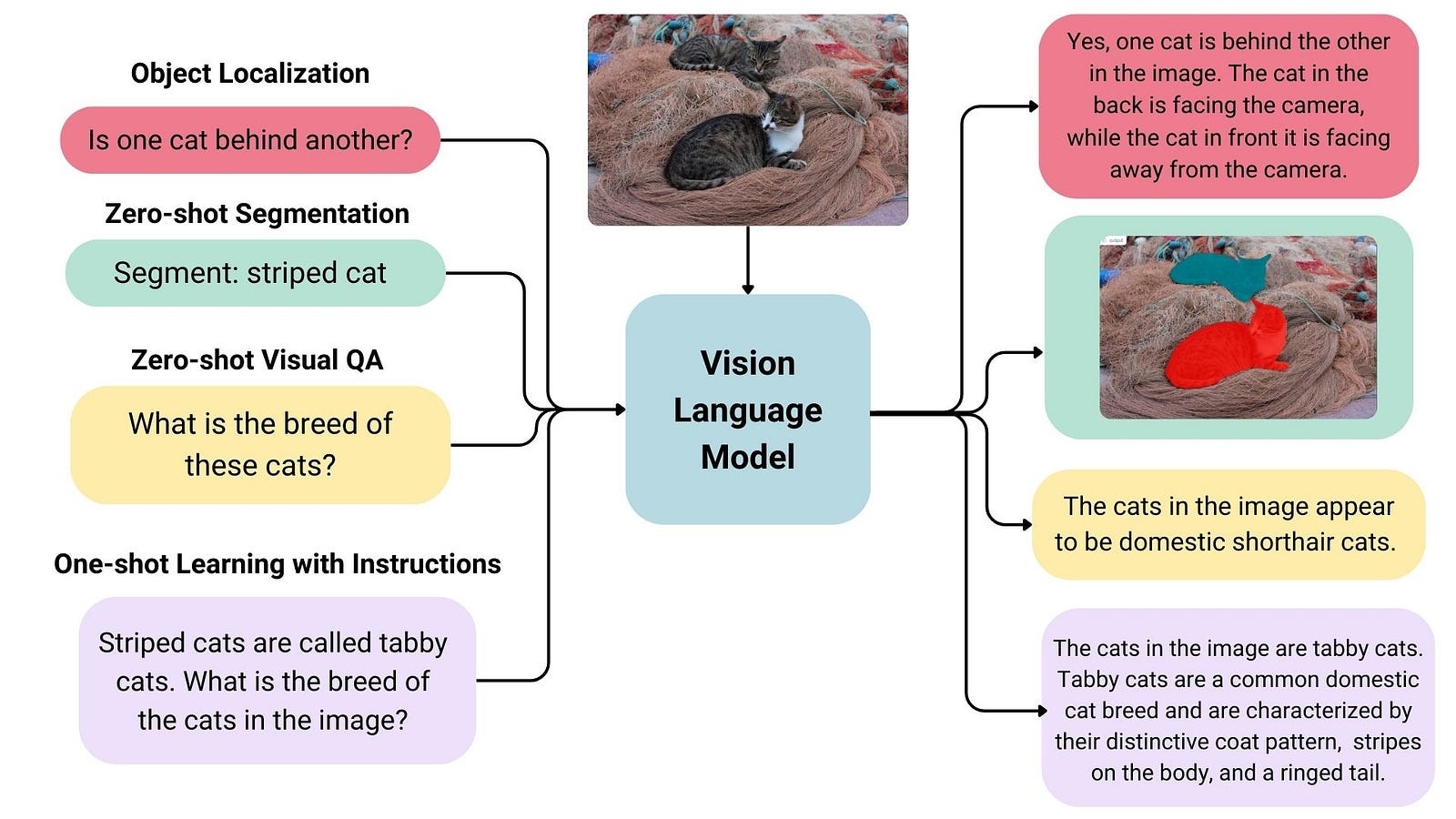
Vision-Language Models (VLMs) are a fascinating class of AI models designed to understand and generate content that bridges the gap between visual information (images, videos) and textual language.
They are built to process and correlate information from these two distinct modalities, enabling them to “see” and “talk” about the world in a more holistic way, much like humans do.
VLMs typically consist of two main architectural branches: a vision encoder and a language model, along with a mechanism to fuse information between them.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.